杨 涛,解 庆,刘永坚,刘平峰
1.武汉理工大学 计算机科学与技术学院,武汉 430070
2.武汉理工大学 经济学院,武汉 430070
随着互联网的发展,海量的长篇文本如新闻、微博、博客、论文等等,充斥整个网络,大大加剧了文本信息获取的难度。自动文摘需求急剧增加,研究如何利用自动摘要技术对长文本的主要内容进行提取总结变得尤为重要。
自动文摘技术经过多年的发展,主要有两种思路,一种是直接从原文中抽取重要句子组成摘要,称为抽取式摘要技术。另一种是在理解原文的基础上,用新的单词或句子表述原始文本的内容,称为生成式文本摘要。目前抽取式文本摘要技术经过多年发展,技术成熟,性能稳定,对于文本的压缩具有显著的效果。但本身存在固有缺陷,摘要的形成方式只是典型语句的机械拼接,不符合人类的摘要习惯,阅读性较差,不适合作为正式阅读的参考摘要。基于BERT预训练模型和强化学习技术的抽取式摘要模型是目前效果最好、性能最为稳定的模型之一。
相比于抽取式文本摘要,生成式文本摘要能够用新的句子来表达原始的文本信息,创建更加精准、自然的摘要。且生成的摘要具有可读性强、语法正确、连贯性强等优点。目前,主流的生成式文本摘要模型主要使用借鉴于机器翻译的基于编码器-解码器架构的Seq2Seq模型[1]。但该类生成式文本摘要模型一般只适用于处理短文本,对于稍长的输入序列的处理能力十分有限。尤其在处理中文数据集时,其处理能力最多只有300~500字(如图1所示)。一旦超过这个长度,其性能会急剧下降,各项指标会趋近于零。但是,在实际的应用场景之中,针对短文本进行自动摘要的意义有限,长文本摘要的需求更大,也更加迫切。因此,目前急需一种性能稳定的针对较长文本的自动摘要算法。

图1 指针生成网络模型效果变化图Fig.1 Pointer-generator network model effect variation
主题模型是近20年发展起来的一种重要的文本信息挖掘技术,已经成为篇章级的文本语义理解的重要工具。主题模型善于从一组文档中抽取几组关键词来表达文档集合的核心思想。多年来,一直被用于多文档摘要任务,并且表现突出。同时,也为情感分析、文本生成、信息检索、文本分类等其他自然语言处理任务提供重要支撑[2]。对于长文本摘要问题,主题模型可以从多语义角度抽取出现在文中不同位置的主题信息。尤其对于多主题长文本,主题模型能以一组概率的形式表达其复杂的主题情况,这对长文本的摘要生成具有显著的指导意义。
鉴于以上背景,本文提出了一种基于主题感知的抽取式与生成式结合的混合摘要模型TASTE(topic-aware abstractive summarization with text extraction)来处理长文本的自动摘要问题。该模型结合了抽取式模型与生成式模型,将两者的优点进行结合,缺点相互弥补。该模型既能保留抽取式文本摘要方法的应对长文本的概括压缩能力,又能保留生成式文本摘要方法的重写能力。另外,为了应对长文本复杂的语义环境及多主题的情况,本文加入了主题感知部分,让原文档的潜在主题参与关键句子的抽取和最终摘要的生成。
1.1 主题模型
主题模型旨在从文档级别的单词共现中发现其潜在主题,通常采用基于贝叶斯图形模型的LDA(latent Dirichlet allocation)方式实现[3]。然而,这些模型都依赖于专业知识参与来定制模型的推理算法。随着主题模型的表达能力越来越强,为了捕获主题相关性和利用已有的条件信息,推理的方法就会变得越来越复杂,会大大增加模型的使用局限性。另一方面,随着深度学习技术在自然语言处理领域的广泛应用,结合深度学习思想与方法的神经主题模型开始广泛使用,并表现突出。不同于传统的LDA模型[3],该模型基于变分自动编码器(variational auto-encoder,VAE)实现[4],同样采用编码器-解码器结构。同时,神经主题模型基本摒弃了传统的概率主题模型关于Dirichlet先验假设和Gibbs采样方式[5],而是直接将复杂的分布计算完全交给神经网络的节点和权重矩阵,通过反向传播算法或随机梯度下降算法训练模型参数,降低了主题模型的使用门槛。此外,由于构造出了神经网络结构,即可以在模型的输入层叠加词向量,从而更好地利用词汇之间的语义信息,发现潜在主题。同时可以更加完美地与其他深度学习模型相互融合,用以辅助训练[6]。于是本文的模型选用了Miao等[7]提出的神经主题模型来推断潜在主题。
1.2 抽取式文本摘要
自动文本摘要技术早期的研究都集中在抽取式文本摘要领域。其多年发展中,前后经历了基于文本特征、基于词汇链、基于图、基于深度学习方法的四个阶段。近年来,随着BERT预训练语言模型的提出[8],出现了众多混合多种先进技术的抽取式摘要模型。如Narayan等[9]提出将摘要抽取任务视为句子排序任务,并引入强化学习技术,使用ROUGE评价指标来作为奖励直接指导模型训练。Liu等[10]将BERT模型的使用方法进一步简化和推广,提出了一个用于抽取式模型和生成式模型的一般框架:在BERT模型之上,通过堆叠多个句子之间的转换层获得抽象的文本表示,以此文本表示抽取摘要句子。并根据模型效果微调BERT模型,该方法成为了使用BERT预训练语言模型抽取文本句子的基础模型,后续不断有研究者在此基础上得到了各种BERT的衍生模型。2020年,Zhong等[11]将抽取式文本摘要的粒度从句子级别ROUGE值调整到摘要段落的ROUGE值,将文本抽取任务视为语义文本匹配问题,使用一个简单的匹配模型来抽取摘要,并对抽取结果使用Tri-Blocking(三元组)等技术进行冗余去除,使得模型的摘要效果更加优异。
1.3 生成式文本摘要
生成式文本摘要实现难度较大,早期发展缓慢,直到2014年,编码器-解码器结构模型在机器翻译上的成功[1],为生成式文本摘要提供了新的思路。2015年,Rush等[12]率先将基于注意力机制的编码器-解码器模型运用到生成式摘要中,将生成式模型的摘要效果提高到一个新的高度。后来学者纷纷基于该模型进行改进创新。2016年,Nallapati等[13]将指针网络引入到编码器-解码器模型中来,用以解决文本生成的OOV问题。2017年,See等[14]在此基础上进一步改进,引入覆盖机制,同时结合指针网络提出了指针生成器模型。该模型完美地解决了生成式摘要的OOV词和摘要重复问题,使生成式文本摘要渐渐成熟。Wang等[15]认为高质量的抽象摘要不仅应将重要的原文本作为摘要生成来源,而且还应倾向于生成新的概念性词语来表达具体细节。在指针生成器的基础上提出了概念指针网络(concept pointer network),用以获得抽象性更高,概念性更强的摘要。Liu等[16]提出对抗训练的指针生成器,该方法除了训练指针生成器外,还训练了一个摘要鉴别器,鉴别器负责将机器生成的摘要和人工生成的参考摘要进行区分,文中使用强化学习方法来优化生成器使得鉴别器的出错概率最大化,通过生成器和鉴别器的对抗训练来提升摘要质量。
目前,随着深度学习技术、强化学习技术、预训练语言模型等技术的发展,出现了各种技术交织的摘要生成模型。随着硬件设备的进步,模型规模与训练速度也大大提升,无论是抽取式摘要技术还是生成式摘要技术,增强模型自身对于文本内容的理解是模型训练的核心,也是实现机器摘要比肩人工摘要的关键。
在本章中,将详细描述本文提出的主题感知混合模型(TASTE),该模型由神经主题模型和抽取-生成混合模型组成。主题模型首先获取文本的潜在主题表示,再加入到混合模型中辅助长文本的摘要生成,获得契合主题的摘要。下面将给出神经主题模型和抽取-生成混合模型的实现细节。
2.1 神经主题模型搭建
根据Miao等的描述,该模型基于变分自动编码器(VAE)实现[17],模型以文档句子的词袋向量作为输入。首先将原文档的句子处理成词袋向量xbow,xbow是一个基于词汇表的V维向量。该神经主题模型同样基于编码器-解码器结构实现,其过程类似于数据的重构过程,如图2所示。

图2 推理模型q(z|d)和生成模型p(d|z)的网络结构图Fig.2 Network structure diagrams of inference model q(z|d)and generation model p(d|z)
编码器部分使用带有激活函数的多层感知机MLP(multilayer perceptrons)来计算先验变量μ和σ,用于生成潜在主题表示θ的中间变量z。

其中,g(·)表示Gaussian SoftmaxgGSM(x)。

以上公式表明,模型使用了一个基于高斯分布的神经网络来参数化潜在变量θ,使用MLP构造了一个推理网络来近似后验概率p(θ|d)。通过使用高斯先验分布,模型可以使用重新参数化的技巧来为变分分布构建无偏和低方差梯度估计。在没有共轭性的情况下,参数的更新仍然可以从变分下限直接推导出来,只是模型训练的速度较慢一些。通常,可以将权重矩阵当做具体主题词的分布,该矩阵负责将高斯样本z转换成主题比例θ。
模型解码器部分会根据获取的主题表示θ进行基于词袋向量表示的重构,对于文档中的每一个词根据θ来提取对应的主题-词分布,结合所有分布获得
该神经网络的训练函数如下:
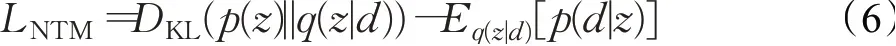
该损失函数是基于变分下限,包括重构损失和隐空间约束损失(使用KL散度衡量)。其中p(z)表示标准的高斯分布,q(z|d)和p(d|z)表示图中编码器和解码器的工作过程。该神经主题模型为独立模块,既可以与摘要模型联合训练,也可以单独训练,训练完成后根据模型计算出潜在主题θ,参与到摘要的生成。
2.2 抽取-生成混合模型搭建
2.2.1 抽取器
抽取器部分使用BERT预训练语言模型作为编码器将输入序列D={s1,s2,…,sn}映射到句子表示向量H={h1,h2,…,hn},其中hi表示文档中的第i个句子,然后解码器利用H从D中抽取一个句子子集在Liu等[10]的基础上,对模型的输入设置进行了稍加修改。由于原BERT模型的输出是依托于输入中的[CLS]符号,而不是每一个句子,若需获得每一个句子的语义表示,则需要在每个句子前面添加[CLS]标记,在每个句子的末尾添加[SEP]标记,以此分割长文本,区分多个句子。则BERT输出层的第i个[CLS]符号的向量就对应第i个句子表示hi。抽取器整体架构如图3所示。
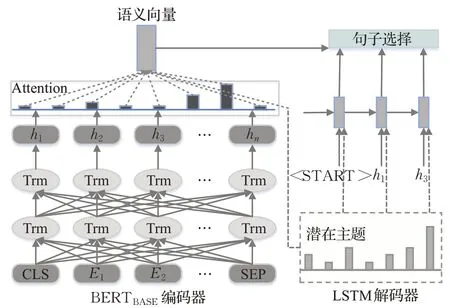
图3 抽取器模型整体架构图Fig.3 Extractor model overall architecture diagram
根据BERT编码得到句子的向量表示后,解码器需要反复抽取句子,既要达到尽量信息覆盖的效果,同时又要避免信息冗余。其具体实现如下,首先获取基于BERT模型的句子编码表示:

解码器部分使用单层单向的LSTM,以上一时刻抽取的句子的编码表示为输入,循环提取句子。同时,为了针对长文本的主题信息进行抽取,在解码器环节添加了潜在主题,并修改了注意力机制的构成部分。

其中,vg、Wg1和Wg2是可学习参数。[;]表示向量的拼接。可以将注意力分布αt视为输入文档中各个句子结合潜在主题的概率分布。根据注意力分布αt可以计算语义向量et,根据et、hi来计算每个句子的被抽取概率:

其中,vp、Wp1和Wp2是可学习参数。t表示解码步骤t时刻,jk代表所有之前抽取的句子。解码器分为两步执行,相当于执行了两次注意力机制,首先处理hi获得上下文向量et,然后根据et获取抽取概率。整个模型类似于一个分类模型,当遇到结束符或超过指定阈值,模型就会停止抽取动作。
2.2.2 生成器
生成器的主要目的是将抽取器抽取的句子压缩改写为简明的摘要句子,以符合人类的摘要习惯,增强阅读性。本文使用See等[14]提出的指针生成网络(pointergenerator networks)作为生成器网络模型,同时结合潜在主题生成以主题为导向的最终摘要,生成器整体架构如图4所示。

图4 生成器模型整体架构图Fig.4 Abstractor model overall architecture diagram
该模型带有指针生成器和覆盖机制,可以较好地解决未登录词和摘要重复问题。生成器根据抽取器获得抽取句子的编号,找到对应句子,对句子进行预处理。由于生成器网络本身是以单个词为最小结果单位,所以无法使用抽取器所训练的句子向量表示。实际上被送入生成器中的是被抽取句子分词以后的词向量表示。该生成器网络模型使用标准的带注意力机制的编码器-解码器结构,编码器的作用在于将输入文档编码成向量表示,输入序列中的原文单词wi被逐个送入编码器,产生一系列编码器隐含状态hi:

生成式摘要是以单词为产出单位,生成目标摘要时也需要加入潜在主题与前一时刻生成的单词相结合,用以辅助摘要生成,同时修改注意力的构成部分:

其中,vT、Wh、Ws和battn是可学习参数。[;]表示向量的拼接。注意力分布αt可看作是当前时刻输入原文序列中结合潜在主题的单词概率分布,概率分布较大的单词是能产生当前解码输出的核心主题单词。注意力分布αt和编码器隐含状态hi进行加权和操作,产生语义向量h*t。在解码步骤t时刻,根据解码器状态st和语义向量h*t可以产生词汇分布Pvocab:


其中,V、V′、b和b′是可学习参数。Pvocab是词汇表(词汇表是事先定义好的,在本文中取训练集词频最高的前50 000个词)中所有单词的概率分布。
由于生成器存在词汇溢出问题,需要引入复制机制。利用指针网络来计算概率决定是根据词汇分布Pvocab从词汇表中生成单词,还是根据注意力分布αt来直接复制输入序列中的单词。根据语义向量h*t、解码器状态st和解码器输入xt计算指针开关pgen。根据pgen决定词汇来源,为了增加主题词在摘要中的出现概率,将潜在主题添加到开关计算部分:

其中,σ为softmax激活函数,均为参数矩阵,bptr为偏置项。
生成式摘要容易出现摘要自我重复,其原因是注意力机制反复注意到输入序列中的某些单词,而覆盖机制的思想就是避免已经获得高注意力的词汇再次获得较高注意力。具体实现为通过以往注意力的权重来影响当前词汇的注意力计算。首先需要根据注意力分布αt汇总计算覆盖矢量ct,ct代表历史注意力信息,利用ct计算当前词汇注意力,同时定义覆盖损失,参与主损失函数计算,即:

根据公式可知,若某一词汇之前已获得高注意力,则其历史注意力信息ct偏大,covlosst等于,为降低损失,必然要降低该词汇的再次注意力,这样就不会再次注意到该词汇,从而解决了重复问题。
该混合摘要模型涉及三个模块,即主题模块、抽取器和生成器。主题模块可以视为一个单独模块,可以预先训练,不影响主模型的训练进程,且小数据集的主题模型训练运算量相对较小,一天以内就可以收敛到一个不错的范围。主模型主要是抽取器模块和生成器模块,在常规摘要算法中直接使用生成式模型对长文本进行逐个字的摘要生成的计算复杂度远高于抽取式方法,这也是抽取式模型的文本处理能力强于生成式模型的一个重要原因。如一篇n字的文本分为m句话,生成器使用的词汇表维度为Vvocab,抽取器和生成器的时间复杂度大致估算如下:
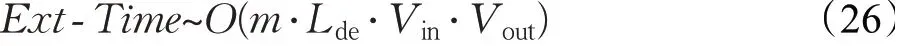

Vin表示输入维度,Vout表示输出维度,Lde表示解码器部分的神经网络层数。当文本长度n较大时,复杂度会急剧增加,加之生成器模型无法并行计算,生成器模型的运算就会变得非常缓慢,影响运行效率。本文结合两种摘要方式,首先利用抽取器压缩文本规模,大大缩减了生成器模块的计算量,是针对长文本摘要来说采取的一种较为合理的降低复杂度的方式。
基于实验发现,本文将模型分为主题模型,抽取器和生成器三个模块分别进行工作时,实验效果不佳,无法找到共同收敛点。于是改进了实验,让三者联合训练。同时由于神经主题模型和抽取器、生成器模型共同训练的时候,神经主题模型的收敛速度要远远慢于混合模型。因此,每对神经主题模型进行100个epoch的预训练,对抽取器模型只进行一个epoch的训练,同时建立联合损失函数:

其中,α和β是为了平衡各个子模型而设置的超参数。
最后使用维特比算法的贪心形式——集束搜索(beam search)来生成最终摘要。集束搜索衡量了搜索空间和获取到最优解的概率双重因素,模型设置集束搜索的集束宽度为10,即每次只保留概率最大的10个结果继续按照词表搜索,直到生成动作结束。同时,借鉴于Zhong等[11]处理冗余的trigram blocking思想,在集束搜索时加入一个rerank操作,即每次对集束搜索生成的10个句子进行一次重新排序。排序的依据为2-grams的重复次数,要求2-grams的重复次数越小越好,以此降低生成摘要的冗余情况。
本章报告本文模型在真实数据集上进行长文本摘要的实验结果。
3.1 数据集与评价指标
在本次实验中,为了验证本文所提出模型的可行性和有效性,模型同时在英文数据集和中文数据集上进行了相关实验。中文数据集选用NLPCC2018共享任务3提供的中文单文档语料库TTNews。该数据集包含50 000条训练数据、2 000条验证集和2 000条测试集(无参考摘要)。该数据集是一个长文本摘要数据集,其平均长度统计如表1所示。与经典的LCSTS数据集相比,该数据集的实验效果更具有说服力。

表1 TTNews文本长度统计Table 1 TTNews text length statistics
英文数据集选用CNN/Daily Mail数据集。该数据集是文本摘要领域的经典数据集,众多突破性实验都是在该数据集上实验成功的。该数据集将近30多万条训练数据,10 000余条验证集数据、10 000余条验证集。该数据集不但数据量足够庞大,而且文本数据长度较长,适合本实验。数据以及参考摘要的质量较高,生成的摘要效果更好,其平均长度统计如表2所示。

表2 CNN/Daily Mail文本长度统计Table 2 CNN/Daily Mail text length statistics
评价指标方面依旧采用文本摘要领域经典的ROUGE指标对模型生成的摘要进行评估。采用广泛使用的ROUGE-1.5.5工具包进行效果检验。由于ROUGE工具无法直接对TTNews中文数据集使用,若使用分词以后的数据进行评判效果差异较大,不具备说服力。于是将中文字符转换为数字ID,再进行ROUGE评估。
3.2 数据预处理和参数设置
在实验之前需要对数据集中的数据进行清洗,并进行一些预处理。其中CNN/Daily Mail比较经典,直接按照See等[14]的做法,使用斯坦福大学的Standford CoreNLP工具包进行分词处理,去除其中的特殊符号,由于本文是针对长文本展开讨论,所以去除掉原文本中长度小于300个字符的数据,留下较长的数据进行实验训练。
对于TTNews数据集,首先过滤掉重复的新闻摘要对和无效的新闻摘要对(无效情况包括:(1)缺少摘要;
(2)缺少原始新闻;
(3)新闻和摘要不匹配;
(4)原文本长度小于300)。采用jieba分词工具进行中文分词。同时,文中的模型是分为抽取器和生成器两块进行实验的,抽取器需要获得抽取显著句子的能力。而数据集中只有文档-参考摘要数据。并没有表明每个句子的提取标签。因此,需要制定一个简单的相似性方法来为文档中的句子打上“标签”。使用ROUGE值寻找最相似的文档句子:

di为文档句子,st为参考摘要。选取一定比例的句子打上标签。基于标签使用最小化交叉熵损失进行训练。
关于词向量部分,英文数据集采用了经典的Glove词向量,维度选择为300维。由于目前中文数据集领域缺乏比较权威的中文词向量,实验前期尝试使用过北师大[18]提供的中文词向量。可能由于文本领域或其他问题,实验效果不佳。因此依旧选中了word2vec自动生成词向量,利用模型自主训练。
模型参数设置方面,抽取器模块的编码器部分针对中英文数据集分别使用BERTBASE和BERTBASE-Chinese预训练语言模型。文中使用到的所有LSTM的隐藏层单元大小设置为256。抽取器和生成器都使用Adam优化器(模型同样尝试了SGD和Adagrad优化器,实验表明,不同优化器经过训练都可以使得模型向最优点收敛,只是训练的时间存在些许差距。),初始学习率都为1E-3,L2正则项系数都为1E-5。对于主题模型,设置主题数K=15。当抽取器、生成器与主题模型三者一起联合训练时,通过实验发现(如图5所示),设置各个损失函数的权重接近时,模型效果最佳。则设置损失函数的调节参数α和β都等于1。对于集束搜索,设置集束宽度(beam size)为10,设置词表大小为50 000。

图5 α和β系数变化影响图Fig.5 α and β coefficient change influence diagram
最后,模型在NVIDIA GTX1080TI GPU上进行了实验,整个模型接受了40个小时的训练。
3.3 实验结果分析
3.3.1 复杂度分析
基于BERT预训练模型的抽取器编码器在训练阶段,由于参数量较为庞大,需要4块显存11 GB的GPU进行长达40个小时的训练。鉴于BERT模型的兼容性和普适性,模型一经训练完成,将适配多种领域的文本内容进行摘要。同时,由于本文将长文本摘要工作分成了抽取器和生成器两部分完成。减低了生成器的数据处理量,且生成器模块的训练可以与抽取器模块的训练同时进行。所以整个模型的训练速度仍然比单纯使用生成器进行文本摘要的速度快。整个模型的训练复杂度对比如表3所示。

表3 各模型训练复杂度对比表Table 3 Comparison table of training complexity of each model
3.3.2 CNN/Daily Mail
表4为CNN/Daily Mail数据集上的实验结果,表5为该数据集上的摘要对比示例。由于对数据集中小于300个字符的数据进行了去除,而大部分模型对这部分短文本的测试数据集的生成效果都极好,指标评价分数都较高,所以本文特意根据对应论文中给出的代码链接复现了相应模型,再用同样处理的数据集进行测试。由于都是针对较长文本进行的测试,实验效果并没有原始论文中给定的那么好(TTNews数据集同理)。具体的对比模型如下:

表4 CNN/Daily Mail(length>300)各模型结果评价表Table 4 CNN/Daily Mail(length>300)evaluation table for each model result 单位:%

表5 CNN/Daily Mail数据集摘要示例Table 5 CNN/Daily Mail dataset summary example
Lead-3:最传统最简单的抽取式摘要模型,只需要选择文档的前三句话来组成摘要的基线模型,其模型效果却非常出色,甚至超越很多复杂的深度学习模型。
Pointer Generator(后面简称P-Gen)[14]:由See等[14]提出,为生成式摘要领域的里程碑式工作,该模型提出的指针生成器和覆盖机制完美的解决了生成式文本摘要的OOV词和摘要重复的两大难题。
fast_abs_rl[19]:由Chen等[19]提出的一种较为复杂的强化选择句子改写模型。该模型是典型的两阶段式摘要模型,由一个抽取器和一个生成器组成,其中抽取器首先从源文档中抽取出显著句子,然后生成器重写抽取的显著句子以获得一个完整的摘要。同时,该模型也是本文的基线模型。
REFRESH[9]:将抽取式文本摘要任务视为句子排序的Ranking问题,是首个使用强化学习的方法替代传统的交叉熵损失训练方法的模型。
Bottom-Up[20]:由Gehrmann等人提出的一种自底向上的摘要方法,也是一种两阶段式摘要模型,第一阶段先做序列标注,找出原文中可能与摘要相关的单词。第二阶段,使用这些相关的词汇为约束,进行生成式文本摘要。
表4中,TASTE表示本文的模型,TASTE-a表示抽取器和生成器均为未添加潜在主题,TASTE-b表示只在抽取器中添加潜在主题,TASTE-c表示只在生成器中添加潜在主题,TASTE表示在抽取器和生成器中均添加潜在主题。同时文中用方框圈出了潜在主题分布中权重较高主题词,进一步说明了主题模型对于长文本摘要的指导意义。
从表4中的数据可以看出本文模型实现了最好的模型效果,相对于同类型的模型有1~2个点的提升。但同时也注意到,只在生成器中添加潜在主题,对模型的效果提升较为明显。通过分析发现,主要是由于该潜在主题模型是基于文档主题词建立的一种“特殊”的注意力机制,是一种基于词级别的注意力机制。而在抽取器模型中,抽取粒度是句子级别的,以词级别的注意力来辅助句子级别的摘要抽取,效果可能不是特别明显。而另一方面,在生成器中,摘要以单个的词为产出单位,形成了词级别的注意力和该主题模型提取到的潜在主题是一个维度上的。相当于是对原来的注意力进行了又一次检验:若原注意力机制与该潜在主题同时注意到某个词语,则这个词语的注意力就被增强了。若之前的注意力注意到了某个错误的词语,而主题模型没有发现,则两者叠加,就可以削弱该词的注意力。从而缓解摘要模型造成的“错误”。
3.3.3 TTNews
同样由于模型去除了该中文数据集中300字以下的数据。只留下文本长度较长的数据进行实验,实验获得的指标数据与NLPCC2018公布的参赛数据不具备可比性,所以未与该类模型数据进行比较。只针对同样数据集下所复现的相关模型进行了比较。表6为TTNews数据集上的实验结果,表7为该数据集上的摘要对比示例。

表6 TTNews(length>300)各模型结果评价表Table 6 TTNews(length>300)evaluation table for each model result 单位:%

表7 TTNews数据集摘要示例Table 7 TTNews dataset summary example
表6中的数据可以看出,在中文数据集中,传统的坚实的Lead-3模型与其他模型差距拉大,主要由于中文的较长文本中,往往前三句是关于一些基础背景的描述并不涉及核心主题。所以模型捕捉不到长文本的核心内容,效果不佳。另一方面,模型也出现了和英文数据集中一样的情况,对于只在生成器中添加潜在主题,对模型的效果提升较为明显。在具体实验中,发现该基于主题的摘要有时也会出现一些纰漏,其在一些娱乐类、故事类、剧情类等具有较强连贯逻辑的文本中,摘要效果会出现下滑。本文在实验时对该部分数据集进行了避让。同时,模型在时政类、报道类等以信息平铺为主的文本中实验效果较好,如何针对所有领域文本都可以实现较好的摘要效果是往后的研究重心。
本文提出了一种基于主题感知的抽取-生成混合文本自动摘要的模型,该模型在早期研究基础上[21],针对长文本摘要中的文本主题指导的重要作用,加入主题感知模块,有效提高了文本摘要的效果和质量。特别对于长文本的处理,该模型几乎可以和人类摘要的方式一样,围绕主题生成摘要,简短精炼,直击主题。同时通过在TTNews和CNN/Daily Mail数据集上的实验结果表明,该模型生成摘要ROUGE分数提升了1~2个百分点,实际的摘要案例也直观表明了本文模型的优势。但对于真正过长的文本进行摘要时,确实存在太多的不确定性因素,出于阅读者和观察点的不同,很难生成令所有人满意的摘要。若可以根据用于在网络上留下的足迹和标签,提前获取用户的阅读喜好,提取用户关注的主题信息,以此辅助摘要生成,则可以实现针对特定用户生成特定摘要的长文本摘要系统,从而全面提升用户体验。在之后的研究中,将向此方向继续努力。
猜你喜欢 解码器编码器向量 基于ResNet18特征编码器的水稻病虫害图像描述生成农业工程学报(2022年12期)2022-09-09向量的分解新高考·高一数学(2022年3期)2022-04-28基于Beaglebone Black 的绝对式编码器接口电路设计*数字技术与应用(2021年1期)2021-03-24基于Android环境下的数据包校验技术分析现代信息科技(2019年18期)2019-09-10浅谈SCOPUS解码器IRD—2600系列常用操作及故障处理科技创新与应用(2017年26期)2017-09-12基于TMS320F28335的绝对式光电编码器驱动设计科技与创新(2017年5期)2017-03-28做一个二进制解码器中国信息技术教育(2016年13期)2016-09-10向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23因人而异调整播放设置电脑爱好者(2015年24期)2015-09-10