陈叶,韩彤,魏龄,于秀丽,李鑫雄
(1.云南电网有限责任公司电力科学研究院,昆明 650217;
2.北京邮电大学 自动化学院,北京 100876;
3.南方电网公司电能计量重点实验室,昆明 650217)
智能电能表是电网采集系统中关键的计量设备,承担着用电数据采集和传输的任务[1],保障智能电能表的正常运行,故障电表维修的及时性,对用电企业、电网公司及家庭用户的切身利益具有十分重要的意义。然而,智能电能表功能的日益丰富,伴随而来发生的故障类型也逐渐多样化[2],此外由于智能电能表的来源不同,国内多家供应商所选择的设备原件、制作工艺有所区别,因此安装后的智能电能表可能发生的故障类型有所差异[3]。当故障发生时,要求检修人员能快速维护,然而实际操作中,运维系统因无法判断具体故障导致故障电能表维修不及时[2]。如何确定智能电能表发生了何种故障,提高智能电能表的检修效率,成为现在电能表检修的一个关键问题。
国内对智能电能表的相关研究中,文献[4]介绍了一种基于RFID的现场智能电能表快速定位手持终端的设计与实现,文献[5]应用Apriori关联规则数据挖掘方法对智能电能表的质量问题进行了分析,文献[6]对低压用电信息系统故障分析与解决策略进行了研究分析,文献[7]设计了一种基于图像处理的自动检测系统,能够实现智能电能表显示面板质量检测的自动化。
目前电网系统的数据中心每天采集智能电能表的运行数据,其中的故障数据信息中包含故障电能表的生产厂家、设备类型、资产编号、投运日期、设备状态、故障发现日期、故障来源、工作时长等相关属性。本文针对采集的电能表历史故障数据信息,利用数据统计、特征选择、采样方法、机器学习中的多分类等大数据分析技术,提出了一种多分类算法融合的智能电能表故障类型预测模型,之后若运行中的智能电能表发生故障时,只需要将该电能表的相关信息输入到该模型中,便可得到相应的故障类型预测结果,并根据此结果快速匹配具备相关维修技能的工作人员,从而提高故障电能表的检修效率,可以降低国家电网在智能电能表运维方面的人力成本和资源成本。
针对智能电能表故障数据集,绘制了各属性与故障类型之间的统计图,初步分析各属性是否可以作为故障预测模型的输入,为后续数据的预处理方法和属性相关度分析提供了依据,并且对智能电能表故障数据集进行故障类型筛选,仅保留部分故障类型进行后续研究,并对特征缺失及异常的样本进行剔除。
1.1 智能电能表故障数据整体统计分析
完成数据的初步处理之后,对样本的故障类型进行统计分析。样本的装置故障共有16种故障类型,每种故障类型的具体名称和对应的样本数如表1所示。

表1 故障类型名称及样本数分布情况表
将各故障类型按样本数量从高到低排序,其中后8种故障类型:故障死机、表箱损坏、时段错乱、高压TA匝间短路、过负荷TA、高压TV匝间短路、断熔丝、TA开路的样本数据量偏少,故不做深入研究,将其相关样本数据删除,并将前8种故障类型分别编号为1~8,后文中故障类型皆用编号表示,对应关系如表2所示。

表2 故障类型名称与编号对应表
从图1可知各个故障类型样本数量占比不均衡,其中1~3类故障占比较大,总计近79%,而7~8类故障占比较小,只占约2%,因此利用此数据集对故障分类预测模型训练时,模型将基于样本较多的故障数据做训练,而属性和小样本的故障类型暂且不予处理,带来的问题是模型容易出现过拟合现象。因此,本文提出了过采样与欠采样相结合的混合采样方法解决数据不平衡的问题。

图1 智能电能表故障类型样本数量分布直方图
1.2 智能电能表故障数据各属性统计分析
将数据集明显与故障类型无关的属性删除,并将目前属性合并整理后,数据集中保留了对故障类型有影响的属性,其中包括生产厂家、设备类型、正常运行时间、故障恢复时间、设备状态、故障来源共6种属性,由于篇幅原因,仅对设备类型与故障类型的相关性进行了统计分析,图2为设备类型与故障类型的分析结果。由于不同类型的设备制造工艺不同,所以导致发生的故障类型也有所区别。

图2 设备类型-故障类型交叉直方图
文中针对智能电能表故障数据中可能存在冗余特征或不相关特征的问题,通过计算特征之间的相关系数,选择不同的特征子集进行对比实验,最终确定了数据集中应该保留的特征。并且针对智能电能表故障数据集中各故障类型样本量差别较大的数据不平衡问题,采用过采样和欠采样结合的混合采样方式解决该问题,并通过对比实验验证了该方式的可行性。
2.1 特征选择
该部分主要通过计算各属性特征与故障类型之间的相关系数,然后选择不同的特征子集基于决策树算法进行对比实验,实验效果最佳的特征子集即为最后选定的特征集合。
各特征属性之间及特征属性与故障类型之间的相关系数公式如下:
假定一个数据集为:
T= {(x1,y1), (x2,y2), … ,(xn,yn)}
(1)
式中xi∈X⊂Rn;
xi是第i个样本数据特征的向量表达;
X为输入空间;
yi∈Y⊂Rn,yi是第i个样本的故障类别标签;
Y是输出空间,且i=1,2,…,n,n为样本个数。
假设数据集有N个特征属性,φk表示第k个特征,k=1,2,…,N。
则该数据集各属性特征与与故障类型之间的相关系数表示为:
r=[ρ1ρ2…ρk…ρN]
(2)
式中ρk表示第k个特征φk与样本标签故障类型之间的相关系数,k=1,2,…,N,且有式(3)所示:
(3)
式中Cov(φk,Y)表示特征φk与样本故障类型Y的协方差;
D(φk)和D(Y)分别表示特征φk与故障类型Y的方差。得到的结果如表3所示。

表3 各属性特征与故障类型之间的相关系数表
文中通过相关性的分析,能够剔除与故障类型关联性较弱的特征属性,降低模型的复杂度,减少训练参数。
考虑到不同特征与故障类型的相关系数差别较大,其中故障恢复时间、设备类型与故障类型的相关性较弱,因此将此二者属性删除,在剩余属性中选择如下三个特征子集:(1)正常运行时间、设备状态、故障来源、生产厂家、故障恢复时间;
(2)正常运行时间、设备状态、故障来源、生产厂家、设备类型;
(3)正常运行时间、设备状态、故障来源、生产厂家、故障恢复时间、设备类型。分别利用如上特征子集,基于决策树算法对智能电能表故障数据集进行学习,然后三个子集分类模型准确率的平均值,结果如下:(1)45.96%;
(2)47.86%;
(3)48.61%。
分析如上数据可以看出利用(3)号特征子集训练所得的模型预测准确率相比较其它子集较高,所以最终选择(3)号特征子集,即保留6个特征属性:正常运行时间、设备状态、故障来源、生产厂家、故障恢复时间、设备类型。
2.2 不平衡数据采样
针对智能电能表故障数据集中存在类型样本数量不平衡影响故障预测的结果及分类模型准确度不高的问题[8-14],本小节基于过采样与欠采样相结合的混合采样,为实现对采样后各类样本数量的灵活调整设定了采样平衡系数,从而确定最佳的训练数据集。混合采样的流程图如3所示,具体步骤如下:

图3 混合采样流程图
(1)统计数据集中每个特征属性对应的样本数量。假设数据集的特征属性类别为M种,每个特征属性的样本数为Num1,Num2,…,NumM。其中Numi表示第i类样本的数据量,i= 1,2,…,M;
(2)确定各类别的采样方式。取所有类别的样本数量的中位数NumMed,若该类i的样本数Numi大于NumMed,则该类别的采样标记为0,即为欠采样方式;
若该类i的样本数Numi小于NumMed,则该类别的采样标记为0,即为欠采样方式;
(3)确定各类别采样后的理论数据量。首先设定采样平衡系数a,a∈[0, 1],如该类采样方式为过采样,则该类理论样本数量=该类原本样本数量-a×(该类原本样本数量-中位数);
若该类采样方式为欠采样,则该类理论样本数量=该类原本样本数量+a×(中位数-该类原本样本数量),具体公式如式(4),类别i采样后的理论样本数为Num_newi,i= 1,2,…,M。
(4)
当假定采样平衡系数a=0.5时,采样过程中的相关数据计算结果如表4所示。
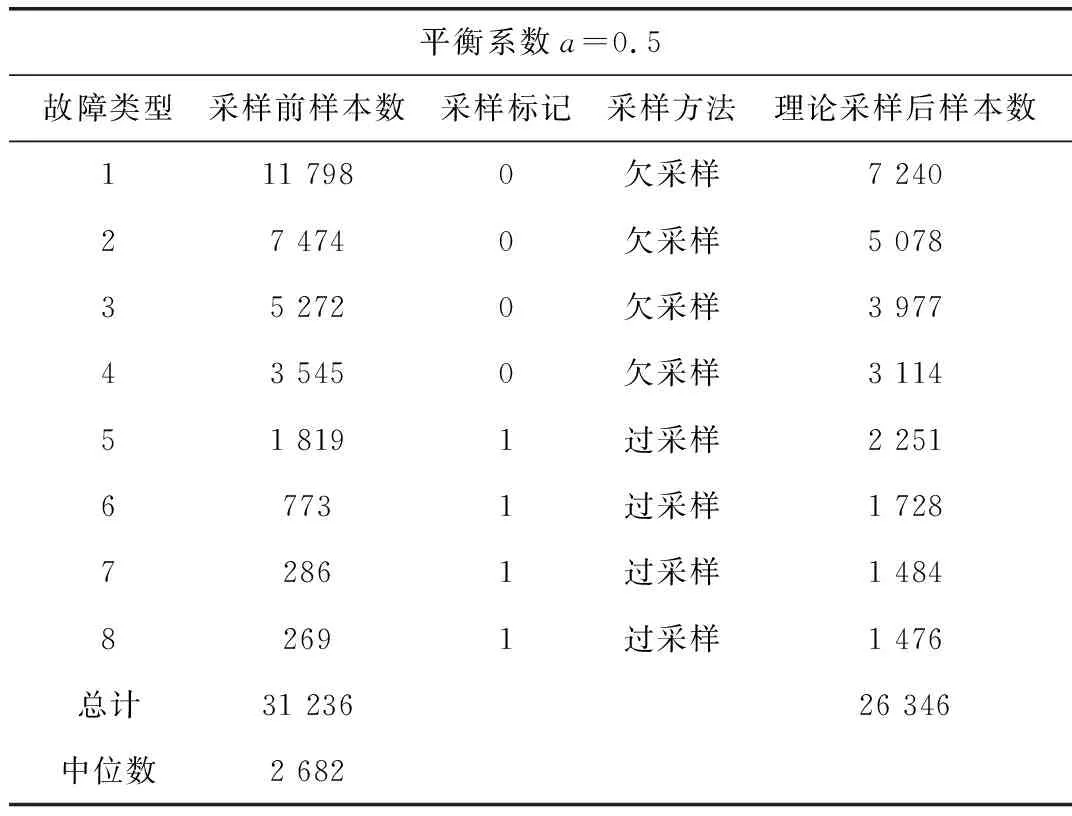
表4 采样过程的相关数据表
3.1 多分类预测模型的评估指标
混淆矩阵是对分类模型进行性能评价的重要工具,通过它可以计算真阳性率、假阳性率、真阴性率、假阴性率、准确率、精确率和F指标等各种评价指标。本文中模型预测精度的评价指标包括:准确率、精确率、召回率和F1分数,正例表示此时正在进行计算分析的类别,其他类别作为反例。如图4所示,TP表示正确地预测为正例,实际为正例;
TN表示正确地预测为反例,实际为反例;
FP表示错误地预测为正例,实际为反例;
FN表示错误地预测为反例,实际为正例。文中所用的分类算法评价指标的计算公式可以由图4的混淆矩阵推导得出,公式如下:
准确率=(TP+TN)/(TP+FN+FP+TN)
(5)
精确率=TP/(TP+FP)
(6)
召回率=TP/(TP+FN)
(7)
F1分数=2TP/(2TP+FP+FN)
(8)

图4 混淆矩阵
3.2 多分类模型融合方法
假设现有模型1和模型2,样本数据集共有M类数据,样本量为n,第k个分类模型训练得到的模型为fk(x),fk(xi)表示该模型对第i个样本的分类结果,k=1,2。假定一个数据集为:
T= {(x1,y1), (x2,y2), … ,(xn,yn)}
(9)
式中xi∈X,xi是第i个样本数据特征的向量表达;
X为输入空间;
yi∈Y,yi表示第i个样本所属的故障类型,Y是输出空间,且i=1,2,…,n,n为样本个数。
ak,j表示第k个分类模型的输出结果中,第j类样本的预测准确率,k=1,2,j=1,2,…M,可得两个模型训练结果中各类别的分类准确率为:
a1=[a1,1a1,2…a1,M]
a2=[a2,1a2,2…a2,M]
对原数据集的各样本类别设置融合标志δ:
(10)
式中aj表示第j类样本的融合标志,值为1表示该类样本的预测输出结果最终取分类模型1的结果,值为2表示该类样本的预测输出结果最终取分类模型2的结果。
对于原数据集中的每一个样本设置融合标志,第j类的所有样本的融合标志等于aj,j=1,2,…M。将数据集按训练集:测试集等于7:3随机划分,基于训练集分别对模型1和模型2进行训练,训练完成后,对于每一个测试样本,根据该样本的融合标志决定进入模型1或者模型2得到输出。
所提方法的基模型个数没有限制,当只有两个基分类模型参与融合为最基础的情形,当基分类模型的数量大于2时,只需要对此方法略做改动也可适用。
3.3 公共数据及实验验证及结果分析
本部分以机器学习权威KEEL[15]数据集中的的5组公共数据作为模型训练集,通过比较各基分类模型和融合模型的准确率来验证本章所提多模型融合方法的有效性。选取的5组公共数据集如表5所示。

表5 公共数据集具体信息
本部分实验将各公共数据集采取随机划分的方法按7:3的比例分为训练集和测试集,首先对SVM、决策树、KNN、随机森林四种基模型进行训练,并得到各模型对测试数据集的预测准确率,然后选取KNN模型和随机森林模型进行融合,得到融合后模型的预测准确率,结果如表6所示,表中的属性准确率增长值等于属性融合后模型准确率减去基模型准确率中的最大值所得的差。
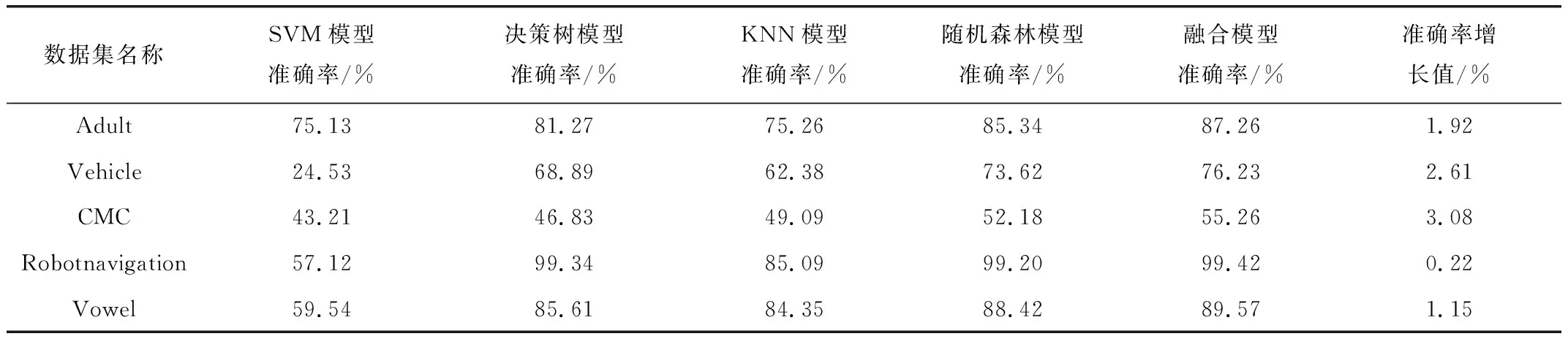
表6 实验结果对比
由表6可以看出,在解决公共数据集的分类问题时,基于本文所提的模型融合方法得到模型准确率相比较基分类模型具有明显提升,说明该方法的普遍使用性和有效性,可以用于智能电能表故障数据集的分类研究。
3.4 智能电能表故障数据集实验分析
为验证所提多分类模型融合方法的有效性,采用常用分类算法中的支持向量机、决策树、最近邻和随机森林算法对智能电能表故障数据集进行训练学习作为对比实验。实验中基分类算法支持向量机、决策树、最近邻和随机森林均使用机器学习常用第三方模块sklearn内封装的功能包实现。
实验过程中,将智能电能表故障数据集采取随机划分的方法按7:3的比例分为训练集和测试集,得到各基分类模型对各故障类别的预测准确率如表7所示。
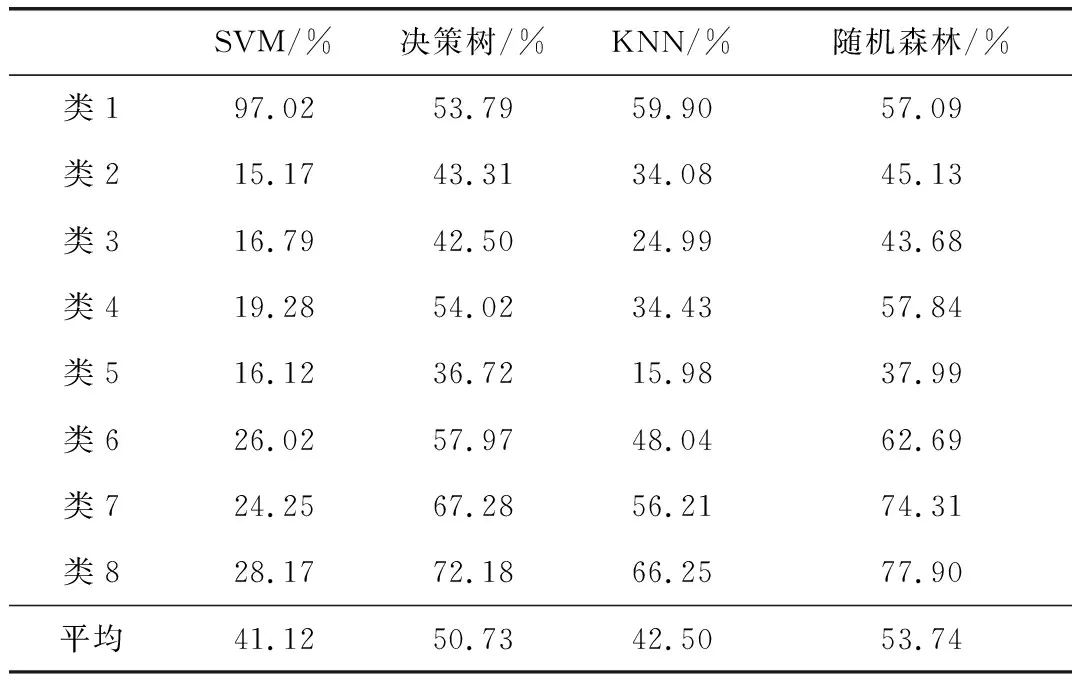
表7 各分类模型对各类别的预测准确率
由表7可以看出,集成学习的随机森林算法预测的平均准确率明显高于其他算法,但是针对某一类样本,如类别1,SVM模型的分类准确率又异常突出,高达97.02%,因此,有必要按照前文中所提的模型融合方法将两种基分类模型进行融合,进一步提高分类准确率。
本部分设置了四个模型融合实验,分别是KNN模型和随机森林模型融合,SVM模型与随机森林模型融合,SVM模型与KNN模型融合,KNN与决策树模型融合,实验中,仍以精确率、召回率和F1分数作为分类模型的评价标准,并且为了排除偶然性对实验产生的影响,每个融合实验重复100次,最后结果取均值,以增加实验结果的可信度,实验结果如表8~表11所示。

表8 KNN模型与随机森林模型融合后结果

表9 SVM模型与随机森林模型融合后结果

表10 SVM模型与KNN模型融合后结果

表11 KNN模型与决策树模型融合后结果
由于篇幅所限,在两者模型融合时的具体过程只以KNN模型与随机森林模型融合为例说明,根据上文中所提融合方法,根据图7中结果,对于类别1,KNN模型的预测准确率高于随机森林模型,因此将类别1中所有样本的融合标志设为1,即此类样本的最终分类结果实际以KNN模型的输出结果为准,而对于类别2~8,随机森林模型的预测准确率高于KNN模型,因此这些类别中所有样本的融合标志设为2,即这些类别的最终分类结果实际以随机森林模型的输出结果为准。确定融合标志之后,在融合模型中进行分类时,每一个样本可根据自身的融合标志自适应的选择进入合适的模型,从而得到相应的分类结果。
由实验结果可以看出,利用所提的多分类模型融合方法,融合后模型的精确率、召回率和F1分数都有所提升,其中SVM模型和随机森林模型融合后的性能提升最为显著,由此可以得出结论,基于智能电能表故障数据集进行分类研究时,所设计的多分类模型融合方法可以提高分类准确率。
基于数据挖掘中的多分类算法,对国家电网公司收集到的智能电能表故障数据集进行分析和学习,并构建故障类型预测模型以解决故障的分类问题,从而提高智能电能表的检修效率。
首先针对智能电能表故障数据集进行故障类型筛选,仅保留部分故障类型进行后续研究,并且对特征缺失及异常的样本进行剔除;
其次,对智能电能表故障数据集的各属性进行初步地统计和分析,并利用可视化手段将结果直接地展示出来,为后续属性相关度分析提供参考;
然后对智能电能表故障数据集进行预处理,提高数据质量以满足构建分类预测模型的需求,根据各属性与故障类型的相关系数大小对数据集进行特征选择,通过对比实验确定最佳的特征子集,剔除了冗余特征或弱相关特征对结果的干扰,并且通过过采样和欠采样相结合的混合采样方式来解决数据集中类不平衡的问题;
最后搭建各基分类模型对智能电能表故障数据集进行训练学习,得到各模型的预测准确率、精确率、召回率和F1分数的结果,提出了一种多分类模型融合方法,并在公共数据集上对该方法进行验证,并最终在智能电能表故障数据集上进行实验,实现了多分类模型效率的提升。故障预测有助于电网系统运维人员做出合理的解决方案,提高系统运维效率。