王晓东
(上海船舶运输科学研究所有限公司 舰船自动化系统事业部,上海 200135)
在船舶加速航行过程中,柴油机可能会出现燃烧不充分的情况,引发“冒黑烟”现象,造成一定的经济损失。如何有效避免船舶在加速航行过程中出现“冒黑烟”现象已成为船舶运输领域的一个主要研究课题。
近年来,人工智能(Artificial Intelligence,AI)在船舶行业得到了广泛应用,不仅能增加企业的经济效益,而且能提高船舶的航行效率。
1) 应用AI有助于降低船舶行业的企业运营成本,提高企业的生产效率,帮助行业更好地整合资源和优化生产流程。AI技术的发展目标是用机器设备代替人类完成作业任务,并提升作业效率,解放劳动力。因此,降本增效是AI发展的必然结果。对于船舶行业而言,AI可应用于船舶设计研发、建造和运营维护等全过程中,推动整个行业实现降本增效。
2) 应用AI有助于改变现有的商业模式和制造模式,引入外部竞争者,改变传统的产业格局。在船舶行业应用AI技术,能在大幅提升行业运营效率的同时,改变传统的行业运营模式[1]。
AI是计算机科学的一个分支,研究内容包括语言识别、图像识别、机器人、专家系统和自然语言处理等。实现AI的方法主要有决策树算法、随机森林(Random Forest)算法、逻辑回归算法、线性回归算法、朴素贝叶斯算法、神经网络算法、KNN(K-Nearest Neighbor)算法、SVM(Support Vector Machine)算法和Kmeans算法等[2]。本文主要采用AI算法中的随机森林算法和Python软件,结合基于C#语言编写的船舶主动力推进系统上位机软件,实现对船舶柴油机“冒黑烟”现象的预测,通过避免出现“冒黑烟”现象,使船舶柴油机的运行工况良好。
船舶柴油机是一种压缩发火的往复式内燃机,能将燃油热能转变为机械能,主要分为二冲程柴油机和四冲程柴油机2种。柴油机的工作基本原理是:通过活塞的运动压缩空气,使气缸内空气的温度和压力提高,通过喷油器将柴油以雾化的形式喷入气缸内,雾化的柴油遇到高温、高压的压缩空气立即燃烧,产生高温、高压的燃气。燃气在气缸内推动活塞往复运动,这样就可将热能转变为机械能。柴油机的构成见图1。船舶在航行时经常会受某种因素的影响而出现“冒黑烟”现象,造成动力下降、油耗增加[3]和污染物排放超标。引发“冒黑烟”现象的原因有很多,供油系统、燃油系统和进排气系统等发生故障都会导致柴油机出现“冒黑烟”现象,具体原因[2]包括:
1) 供油提前角不正确、供油提前角过大、供油提前角过小和喷油泵柱塞或出油阀严重磨损;
2) 喷油柱塞或出油阀严重磨损;
3) 喷油器雾化不良、卡死或滴油严重和喷油压力不正确;
4) 气缸压缩压力不足、气阀间隙不正确和气缸内压缩阻力减小;
5) 进气管和排气系统存在问题;
6) 燃油质量不佳,设备匹配存在问题;
7) 供气量不足等。
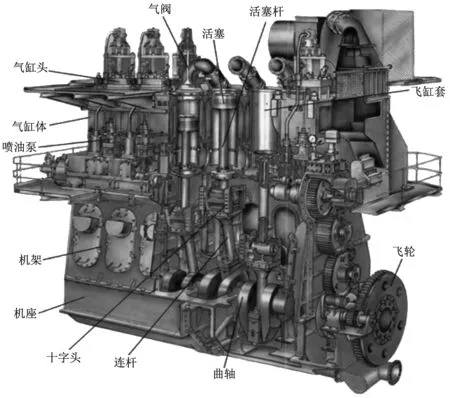
图1 柴油机的构成
若不考虑柴油机本身的故障因素,则“冒黑烟”现象主要在3种情况下出现,分别是主机启动时、主机接排过程中和主机加速过程中。本文主要研究船舶加速航行时出现的“冒黑烟”。当船舶加速航行时,柴油机的输出功率需在短时间内快速增加,即柴油机的转速需快速增加,柴油机油门给定增大。由于柴油机的给油量在短时间内快速增加,而排气压力增加不及时,造成进入气缸的空气量不足,柴油机内的燃油燃烧不充分,从而出现“冒黑烟”现象。当出现“冒黑烟”现象时,由于排气压力是由柴油机的特性决定的,故可适当减小油门给定,或在加速过程中减小柴油机转速的加速斜率。由于不同柴油机的特性不同,故每台柴油机都需根据自身的特性设置油门给定特性。
随机森林算法是一种高度灵活的机器学习算法,是一个包含多个决策树的分类器,其输出的类别是由个别树输出的类别的众数决定的,该算法的原理图见图2。随机森林算法是通过集成学习的思想对多棵分类与回归树(Classification And Regression Tree,CART)进行集成的算法,其基本单元是决策树,在本质上属于机器学习的一个分支,即集成学习(Ensemble Learning)方法。

图2 随机森林算法原理图
随机森林算法的特点包括:准确率高,能有效地运行在大数据集上,能处理具有高维特征的输入样本;
不需要降维,能评估各特征在解决分类问题方面的重要性;
在生成过程中能获取内部生成误差的一种无偏估计,对于缺省值问题也能获得很好的结果。随机森林相关概念包括信息熵、信息增益、决策树、集成学习和bagging。
1) 信息熵表示信息量的大小,信息量越大,对应的熵值就越大。
2) 信息增益在决策树算法中是用来选择特征的指标,信息增益越大,该特征的选择性越好。
3) 决策树是一种树形结构,含有多个节点,每个节点表示1个属性上的测试,每个分支代表1个测试输出,每个叶节点代表1种类别。常见的决策树算法有CART、C4.5和ID3。
4) 集成学习算法的原理是通过对几种模型算法进行组合解决单一预测问题。随机森林算法的工作原理是生成多个分类器或模型,每个分类器或模型独立地进行学习和作出预测。这些预测最后形成预测结果,该结果优于任何一个单分类的分类器或模型的预测结果。
5) bagging也称bootstrap aggregating,是在原始数据集中选择S次之后得到S个新数据集的一种技术,是一种有放回抽样[2]。
随机森林的生成过程:若要对一个输入数据集进行分类,需先将该输入数据集输入到每棵CART中进行分类,再根据所有CART分类结果综合得出分类结论。例如:森林中召开会议,讨论某个动物到底是兔子还是狐狸,每棵树都要独立地发表自己对该问题的看法,即每棵树都要投票选择是兔子还是狐狸。被投票的动物到底是兔子还是狐狸需根据投票情况确定,获得票数最多的类别就是森林的分类结果。森林中的每棵CART都是独立的,99.9%不相关的树做出的预测涵盖所有情况,这些预测结果会彼此抵消。将以上总结起来,即对若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想。“森林”从字面上理解就是由多颗决策树构成的集合,森林中的每颗树都是采用CART算法得出的;
“随机”表示构成多颗决策树的数据是随机生成的,生成的过程采用bootstrap抽样法实现。
在船舶主动力推进系统上位机软件中增加AI模块,通过调用Python语言和随机森林算法模型实现对柴油机“冒黑烟”现象的预测,并显示预测结果,该结果可发给柴油机控制器作为其进一步实施控制的依据。船舶主动力推进系统上位机软件的主要功能包括数据采集、数据显示、报警、数据记录和查询、AI模块等,软件的流程框图见图3。Python作为一种解释型脚本语言,广泛应用于科学计算、大数据统计、AI、软件开发和网络爬虫等领域中。
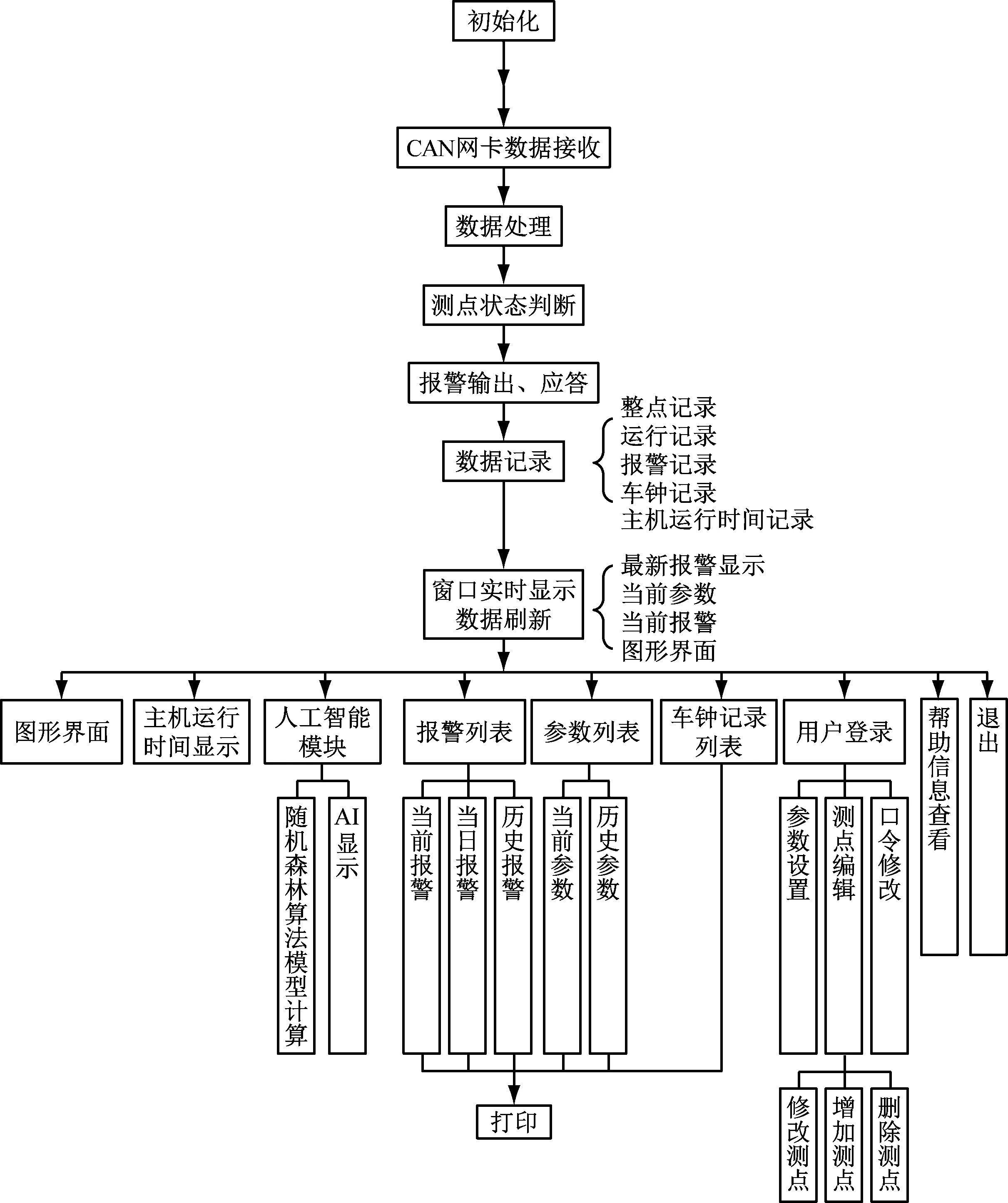
图3 软件的流程框图
本文的柴油机“冒黑烟”现象预测流程如下:
1) 在船舶航行过程中采用船舶主动力推进系统上位机软件实时记录相关参数,并将其保存到数据库中,供Python调用。
2) 软件的AI模块从数据库中提取关键设备的数据,建立数据集,调用Python,根据已提取的大数据,基于随机森林算法模型建模,生成可应用的模型。
3) AI模块输入当前的状态参数到已建立的模型中进行预测,生成预测结果并进行显示。操船人员可根据预测结果进行相关操作。
柴油机“冒黑烟”现象预测流程图见图4。

图4 柴油机“冒黑烟”现象预测流程图
本文采用某艘船12个月的航行数据进行大数据分析,这些数据为船舶每天航行过程中由上位机保存到数据库中的数据,包括主机转速、主机功率、桨角绝对值、油门给定百分比、主机扫气压力和主机是否冒黑烟等。在柴油机烟囱中,传感器探测其排放的烟雾浓度,当达到设定浓度时,认为存在“冒黑烟”现象。由于烟囱内的烟雾浓度不均,故收到“冒黑烟”信号有一定的延迟。当有“冒黑烟”现象时,记录数据为1;当柴油机正常时,记录数据为0。本文将“冒黑烟”现象数据作为特征值,将其他数据作为因变量值。AI模块首先对采集到的数据进行清洗,包括查看数据集是否存在缺失问题、数据是否具有一致性和完整性、数据中是否存在异常值。当数据集存在缺失问题时,采用替换法,使用均值替换缺失值。当数据集中存在异常数据值(指远离正常值的观测,即“偏离”的数值)时,采用删除法,删除偏离的数据。其次,调用Python对数据做训练集和测试集进行拆分。最后,采用随机森林模型对训练集数据进行训练,得到训练好的模型。
采用决策树模型算法作为对比对象,对随机森林模型算法的应用效果进行验证。随机森林算法模型的训练过程如下。
首先,将经过清洗的数据分为训练集和测试集,通过网格搜索法确定最佳组合参数,结果为:决策树最大深度max_depth取值为2;
内部节点再划分所需最小样本数min_samples_split取值为3;
叶子节点最少样本数min_samples_leaf取值为2。Python部分代码如下:
import pandas as pd
from sklearn import model_selection
from sklearn.model_selection import GridSearchCV
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn import ensemble
from sklearn import metrics
data=pd.read_csv(r"C:UsersNeighborWangDesktop01.csv")
data.head()
Speed Power CrewValue ThrolteAdd Presure blachSmoke
0 400 4000 0 0 3.0 0
1 402 4000 0 0 3.0 0
2 405 4002 0 0 4.0 0
3 406 4030 30 8 5.0 0
4 407 4030 30 8 6.0 0
#取出清洗后数据中自变量名称
predata=data.columns[:-1]
#将数据集拆分为训练集和测试集
X_train,X_test,y_train,y_test=model_selection.train_test_split(data[predata],data.blachSmoke,test_size=0.25,random_state=1234)
#预设各参数的不同选项值
maxp_pre_depth=[2,3,4,5,6]#18,19,20,21,22
min_pre_samples_split=[2,4,6,8]#2,4,6,8
min_pre_samples_leaf=[2,4,8,10,12]#[2,4,8,10,12]
parameters={"max_depth":maxp_pre_depth,"min_samples_split":min_pre_samples_split,"min_samples_leaf":min_pre_samples_leaf}
#网格搜索法,测试不同的参数值
#grid_categ=GridSearchCV(estimator=tree.DecisionTreeRegressor(),param_grid=parameters,cv=10)
grid_categ=GridSearchCV(estimator=tree.DecisionTreeClassifier(),param_grid=parameters,cv=10)
#模拟拟合
grid_categ.fit(X_train,y_train)
#返回最佳组合的参数值
grid_categ.best_params_
{"max_depth": 2, "min_samples_leaf": 3, "min_samples_split": 2}
其次,分别采用决策树模型算法和随机森林模型算法进行训练,对比2种模型的训练效果。Python部分代码如下:
#构建用于回归的决策树
#CART_Reg=tree.DecisionTreeRegressor(max_depth=2,min_samples_leaf=3,min_samples_split=4)
CART_Reg=tree.DecisionTreeClassifier(max_depth=2,min_samples_leaf=3,min_samples_split=2)
#回归树拟合
CART_Reg.fit(X_train,y_train)
#模型在测试集上的预测
pred=CART_Reg.predict(X_test)
#计算衡量模型好坏的MSE值
print(metrics.mean_squared_error(y_test,pred))
print(metrics.accuracy_score(y_test,pred))
0.1746031746031746
0.8253968253968254
#构建用于回归的随机森林
#RF=ensemble.RandomForestRegressor(n_estimators=200,random_state=1234)
RF=ensemble.RandomForestClassifier(n_estimators=200,random_state=1234)
#随机森林拟合
RF.fit(X_train,y_train)
#模型在测试集熵的预测
RF_pred=RF.predict(X_test)
#计算模型的MSE值
print(metrics.mean_squared_error(y_test,RF_pred))
print(metrics.accuracy_score(y_test,RF_pred))
0.1111111111111111
0.8888888888888888
如上所述:采用决策树算法模型训练的结果是均方误差为0.174 603 174 603 174 6,准确率为0.825 396 825 396 825 4;
采用随机森林算法模型训练的结果是均方差为0.111 111 111 111 111 1,准确率为0.888 888 888 888 888 8,均方误差有所减小、准确率有所提高,故随机森林算法的表现更出色。根据随机森林算法计算的各变量的重要性绘制条形图,见图5。Python部分代码如下:

图5 变量重要性条形图
#构建变量重要性的序列
importance=pd.Series(RF.feature_importances_,index=X_train.columns)
#排序并绘图
importance.sort_values().plot("barh")
plt.show()
最后,采用训练好的随机森林算法模型进行预测。以船舶当前数据(主机转速为764 r/min;主机功率为4 132 kW;桨角绝对值为65%;主机油门为45%;主机扫气压力为1.4 MPa)为例,将因变量数据值[764,4 132,65,45,1.4]输入模型中,模型根据输入值预测结果输出为“1”,即会出现“冒黑烟”现象。Python部分代码如下:
import numpy as np
x=np.array([764,4132,65,45,1.4])
y=x.reshape(1,-1)
RF_predx=RF.predict(y)
#随机森林
print(RF_predx)
out:1
此时船舶主推进系统上位机软件显示柴油机将出现“冒黑烟”现象并提醒操船人员:若在半自动条件下,则操船人员可适当减小油门增加值,或减小桨角绝对值,直到“冒黑烟”提示消失;
若在自动条件下,则主推进控制设计人员可根据“冒黑烟”提醒记录修改控制程序,例如在车钟由“进2”变到“进3”过程中,根据“冒黑烟”记录修改控制程序中该状态下的油门或桨角增加速率。
本文采用船舶主动力推进系统上位机软件和Python软件,利用AI算法中的随机森林算法,实现对船舶加速航行过程中出现的“冒黑烟”现象的预测,预测结果可发给柴油机控制器作为其进一步实施控制操作的依据。由于本文采用的船舶数据集相对较小,存在数据过拟合的可能性,故对其他船舶不具有一般性的指导作用。若要将该方法应用于其他船舶上,还需重新采集相应的数据。
猜你喜欢 黑烟决策树柴油机 简述一种基于C4.5的随机决策树集成分类算法设计科学与信息化(2019年28期)2019-10-21柴油车尾气烟团不透光烟度仪的优化设计绿色科技(2017年14期)2017-08-22决策树学习的剪枝方法科学与财富(2016年32期)2017-03-04戒姻糖爆笑show(2015年11期)2015-12-17南京尚德柴油机有限公司中国水运(2015年11期)2015-12-08拖拉机因压缩及喷油导致冒黑烟的问题分析吉林农业·下半月(2014年12期)2014-12-25柴油机三种滤清器常见问题及保养要点农机使用与维修(2014年6期)2014-09-23河柴重工新型船用高速柴油机上线装配中国水运(2014年7期)2014-08-11决策树在施工项目管理中的应用决策与信息·下旬刊(2013年1期)2013-03-11船舶柴油机密封条航海(2009年1期)2009-02-23