莫俊铭 郑成勇 戴紫灵
(五邑大学 数学与计算科学学院 广东省江门市 529000)
习近平总书记在2022年3月24日特别指出,要在全国开展全面的安全检查,加大对违法犯罪的查处力度,采取有力的措施,消除各类隐患和风险,坚决制止重大事故,保障人民生命财产的安全。所以,要想进一步提高我国安全生产工作的发展水平,需把习近平的重要讲话精神贯彻到全国。本文研究拟解决的问题--如何精准判别和预测有安全生产隐患的不合格企业,也正肩负起社会的使命,响应时代的号召。
文本分类分为两种,一种是基于机器学习的文本分类,另一种是基于深度学习的文本分类。如何进行文本的分类处理是文本分类的核心工作,该工作有着深远意义的应用前景。深度学习网络通过情感分析进行文本分类,常用到的经典模型有卷积神经网络和循环神经网络,在循环神经网络中常见的是其变体LSTM,BiLSTM通过双向网络连接,能将文本从两个方向同时输入,使模型可以充分地获取句子间地语义信息。随着在安全隐患工作领域对隐患文本进行文本分类技术的应用和创新从未停止,安全隐患文本内容涵盖了隐患的现状,安全隐患的类别以及该隐患对社会安全的危害程度,也是做好安全防护工作的重要依据。本文使用BERT模型对企业安全隐患文本进行文本分类研究,该模型拥有双向编码的能力和强大的特征提取能力,掌握了上下文的语义背景后,词向量的表达形式也会作出对应的改变,因此具备了独特的一语多义的能力。通过BERT预训练模型进行企业隐患文本的全局语义特征表示的生成,进行企业安全隐患文本的分类工作,并进行不合格企业的预测,对比其他经典的深度学习模型和机器学习模型的预测结果,发现BERT模型的分类和预测结果最好。
在自然语言处理中,文本分类是一个非常重要的研究方向,在文本挖掘中发挥着巨大作用。然而,早期的文本分类方法--专家规则(Pattern)分类有很大的不足,它的覆盖范围和精确度都很低。在统计与资讯科技的发展下,互联网上在线文本数量的迅速增加以及对机器学习的深入研究,人工功能工程+分类建模过程逐渐形成。传统的文字表现出了高度的维度和分布问题,表达特征的能力较弱。同时,也要求更高的人工特性。随着深度学习在图像处理和语音理解领域取得的突破性成功,进而也促进了其在NLP上的发展。如今,深度学习模型在文本分类上也有良好的表现。而在安全隐患领域,研究者们也一直秉持着创新的精神进行深入的研究。
目前,文本分类也被广泛地应用在数字化图书馆、舆情分析、新闻推荐、邮件过滤等领域。其中,针对安全隐患文本数据处理的相关研究也有了一定的深度。例如:陈孝慈等基于潞安集团司马煤业有限公司2014年安全隐患记录数据,利用潜在狄利克雷分配模型, 挖掘煤矿安全隐患潜在主题;
谢斌红等基于煤矿安全隐患信息研究了Word2vec和卷积神经网络的煤矿安全隐患信息自动分类方法;
谌业文等以《贵州省煤矿安全信息管理系统》的68家煤矿企业安全隐患记录为样本数据对分类模型进行测试,其文本分类模型准确率达90%以上,并构建了隐患等级评估体系。该分类方法的输入是一种短小值的特征表达矢量,它把特征表达矢量中的错误信息传送到分类器。所以,在短句分类中,如何表达短句的特点是提高其分类能力的一个重要环节。在前人研究的基础上,本文提出一种基于Transformer双向编码器表示的企业安全隐患短文本分类算法,改进短文本特征表达来进行合格企业与不合格企业的排查。
2.1 BERT模型
语言模型的研究已经从“one-hot”、“Word2vec”、“ELMO”、“GPT”到“BERT”模式。使用Word2vec模式进行的词汇向量是一个静态的词汇矢量,而非多态性。GPT是一个不能获得词汇和上下文的单向的语言模式。ELMO是一种很好的解决方法,它可以根据特定的语境,根据不同的语境,动态地产生每一字的嵌入。BERT模型是一种基于深度双向编码和训练的语言理解模型,它可以通过对文本的上下文信息来进行向量表达,也可以表达单词的歧义。该模型主要采用的是双向Transformer网络结构,Transformer模型每层的计算复杂度更优,能用最小的序列化运算来测量可以被并行化的计算且一步计算解决长时依赖问题,该模型的三种优点有利于提高计算效率。不仅如此,Transformer模型还能通过位置嵌入,模型的语言顺序的理解能力也比较好。在第一阶段时为了实现预训练文本任务使用MLM和NSP两种策略,在第二阶段采用Fine-Tunning的训练模式来处理下游任务,Transformer计算目标词与文本中每一个词的相似度作为权重系数,再利用加权求和的方式表示词向量。
BERT模型结构如图1所示。

图1:BERT模型结构
BERT模型提出的MLM和NSP的无监督预测任务,在MLM 与 NSP 任务上对 BERT 模型进行增量训练,前者用于获取词级别表示,后者用于获取句子级别表示,并将两个任务的结果进行结合。经过BERT模型处理后能够获得语境化的词向量,对处理长距离依赖信息的语句具有很好的效果,因此这使得BERT中文模型能更好地适用于语料数据。
BERT模型主要使用Transformer的Encoder部分来代替无法并行实现和运行速度慢的RNN模型从而解决序列问题的Encoder-Decoder结构,Encoder输入嵌入句子中的字,然后添加关于每个单词在句子中的位置的信息,然后经过Self-attention层,当Encoder对每个字进行编码时可以看到之前的信息和序列。Encoder输出通过Add&Norm层。Add是将Self-attention层的输入和输出相加。Norm表示对添加的输出进行归一化处理,使Self-attention层输出具有固定的均值和标准差。其中均值为0,标准差为1,并返回归一化向量列表并传入全连接的神经前馈网络层。类似地,Feed-Forward层也在其Add & Norm层中进行处理,产生一个标准化的词向量列表。Encoder部分的主要模块是Selfattention。它的基本思路是通过对句子中各个单词之间的关系进行计算,并根据它们之间的关系来调节各个单词的权重,从而得出每一个单词的新数值。以这种方式获得的向量比传统的词向量具有更全面的表示,因为它们不仅包含词本身,还包含它们与其他词的关系。
BERT模型使用具有三层涵义的编码,第一层编码是词向量,第二层编码是根据词位置信息进行插入,第三层编码则是体现句子之间独立性的编码。该模型通过整合连接两个句子进行编码的建立,完成三层编码的建立后,继续进行三种embedding的结合,最后输出词向量。
BERT模型将Tanh函数,Soft-max函数,GELU函数作为激活函数分别布置于各个激活层。具体如下:
Tanh函数将负无穷到正无穷的数值映射至(-1,+1)区间,其是由基本双曲正弦和双曲余弦推导而来,具有软饱和性,在深层神经网络训练会出现梯度消失的问题,比较适用于二分类任务。

针对于多分类使用最多的是Soft-max,该函数把一个k维的real-value向量(al,a2,a3,a4,…)映射成(bl,b2,b3,b4,…),这里bi是一个0-1的常数,所以为了达到多分类的目的,我们可以根据bi的大小进行多分类求解(取权重最大的一维)。Soft-max函数为每个类分配概率。前提是对每个元素进行一次取幂运算,并将其全部转换为正数,然后再进行后续运算。其公式为:
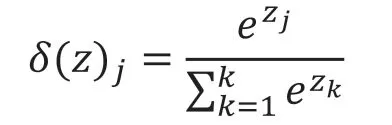
GELU函数是针对解决随机失活函数而创建的,其中随机去激活具有0-1分布,即两点分布,称为伯努利分布,GELU将这个概率分布变为正态分布(正态分布),或高斯分布分布。
高斯误差的线性单元激活函数被内置到Transformer中。其公式为:

一个语言模型在训练完成时参数就已经确定了,但是对于不同的下游任务,利用同一套参数显然是不科学的,如果重新训练又会花费大量的时间。BERT是一个预训练语言模型,为了适应各种不同的下游NLP任务,采用了Fineturning的方式来对已经训练好的模型进行微调,以达到最好的模型匹配效果。
在模型转化器结构内,数据首先通过多头关注模块,以获得一个加权特征向量。在注意力机制中,每个字符都有三个不同的向量,即查询向量(Q)、密钥向量(K)和值向量(V),通过三个特征向量来计算分配给每个词的注意力权重。本文利用缩放点积的方法对注意力机制中的矢量进行了计算,以避免其在内积中过于庞大:
Output=Attention(Q,K,V)

Q、K和V的投影是用h种不同的线性变换进行的,将不同的attention结果进行串联。
MuliHead(Q,K,V)=Concat(h,h,h…h)W

其中W,W,W,W分别是输出层,线性层的权重,m表示字符个数。
最后发送给前馈网络模块,该模块由两层结构组成:第一层是激活函数 ReLU,第二层是线性激活函数。
Output=max(0,WY+b) W+b
其中W,b是第一层的权重和偏差,W,b是第二层的权重和偏差。
BERT模型在自注意力机制的基础上,采用了多头自注意力(multi-head self-attention)机制、具体做法是针对文本进行多次注意力运算,在把运算结果合并起来,即得到多个“注意力头”的集成结果。BERT模型的输出是一个三维矩阵,其中包括批次训练的大小,输入句子的长度,模型的隐藏层大小。在训练期间,模型不但进行正向传播,而且还通过逆向传播来优化模型的参数。因此可以让模型关注到语句不同位置的信息,也可通过不同注意力头的集成缓解过拟合。
BERT模型最大的创新之处在于它在预训练方面是使用的遮蔽词预测方法,以前的语言模型,可能通常是从左向右地预测下一个词,或者是从右向左地预测上一个词,又或者会采用双层双向网络,将两种预测方法进行简单地结合。但由于BERT模型有Transformer结构,由于多层次注意力机制的存在,使得每一个单词的编码都能够获得全部单词的相关信息,而且双向处理是平行的,以前的模型只能在一个方向上进行,这个方法只能在前面的单词被预言之后,再去预测下一个单词,这样的方法效率非常低。BERT模型特有的遮蔽词语言模型训练能极大提高模型效率,在遮蔽词的预训练过程中,模型输入序列中的元素会被随机的特殊记号代替,从而完全屏蔽某一个词在层次编码过程中的全部信息。在对此模型进行编码后,通过对符号的最后输出结果进行预测。
2.2 评价指标
对于二分类问题,基于真实类别和预测类别组合,可形成分类结果的混淆矩阵,如表1所示。基于混淆矩阵,本文选取准确率作为模型的评价指标。正确率是评价模型最常用的衡量标准,它表明了模型的预测或分类效率。
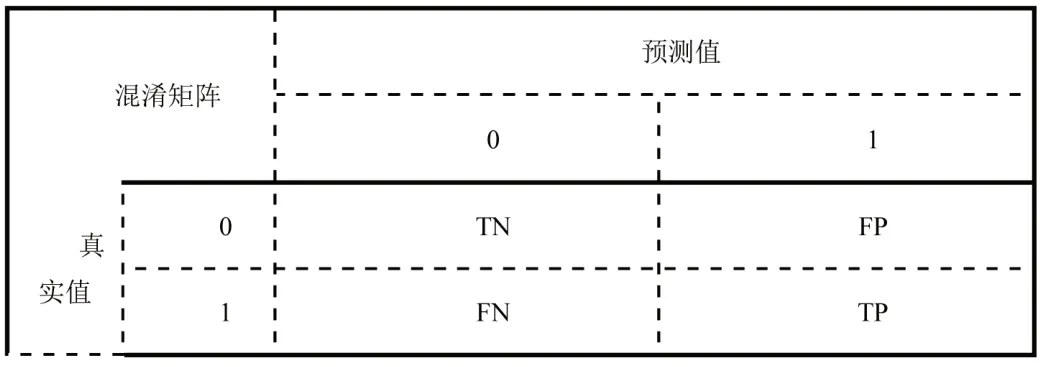
表1:混淆矩阵
在表1中,TN表示真值为0和预期值为0的样本数;
FP表示真值为0但预期值为1的样本数;
FN表示真值为1但预期值为0的样本数;
TP表示真值为1和预期值为1的样本数。虽然本文中的模型在训练后得到的准确率、精确率和召回率三个指标都显示出相对积极的结果。然而,这些衡量标准仍然有一些局限性。而精确率和召回率分别是针对预测结果及原样本而言的,因此本文后期采用了F1值为模型评判标准,对测试集进行预测,并进一步优化模型。
3.1 实验环境及实验数据集
本实验主要基于Python3.7进行编码,使用集成开发环境Jupyter Notebook和Pycharm进行开发,基于scikit-learn框架和Tensorflow框架完成模型搭建。硬件环境中CPU为Intel Core I7-10750H 2.60GHz,内存大小为128GB,GPU为GTX 1650 Ti。
本实验中所有模型使用的训练集和测试集是企业安全隐患文本数据,来源于2021全球开放数据应用创新大赛,具有一级标签,二级标签,三级标签,四级标签,11999条训练数据,17999条测试数据。
针对数据集中大量无用的标点符号、停用词以及特殊字符,为了避免噪声和不必要的特征对模型性能产生不利影响,因此需要对文本数据进行数据清洗。
3.2 模型参数选择
本文在jupyter notebook和pycharm上进行网络训练,搭置好tensorflow环境后,定义深度学习模型BERT和多种机器学习模型的参数,待模型搭建完成后再使用同一企业安全隐患文本作为训练集进行模型训练。其中BERT模型的训练次数为3,迭代抽取的样本数量为32,学习率为0.00001,优化器为Adam,句子长度为128,分类类别数为2。SVM使用rbf作为核函数,惩罚系数为1.0,核函数的参数为auto,停止训练的误差值为0.001。随机森林模型使用的决策树个数为1200,树的深度为15,使用Auto方法设置允许单个决策树使用特征的最大数量,最小叶子节点数目为3,最大叶子节点数为400。BiLSTM使用交叉熵式损失函数,迭代抽取的样本数量为128,优化器为Nadam,迭代次数为30。朴素贝叶斯模型使用交叉熵式损失函数,迭代抽取的样本数量为128,优化器为Aadam,迭代次数为30。
3.3 模型结果比较
本文对训练集中的数据进行数据预处理,数据分析后,对模型进行训练和测试。最终在测试集的各指标数据可视化柱状效果如图2所示。
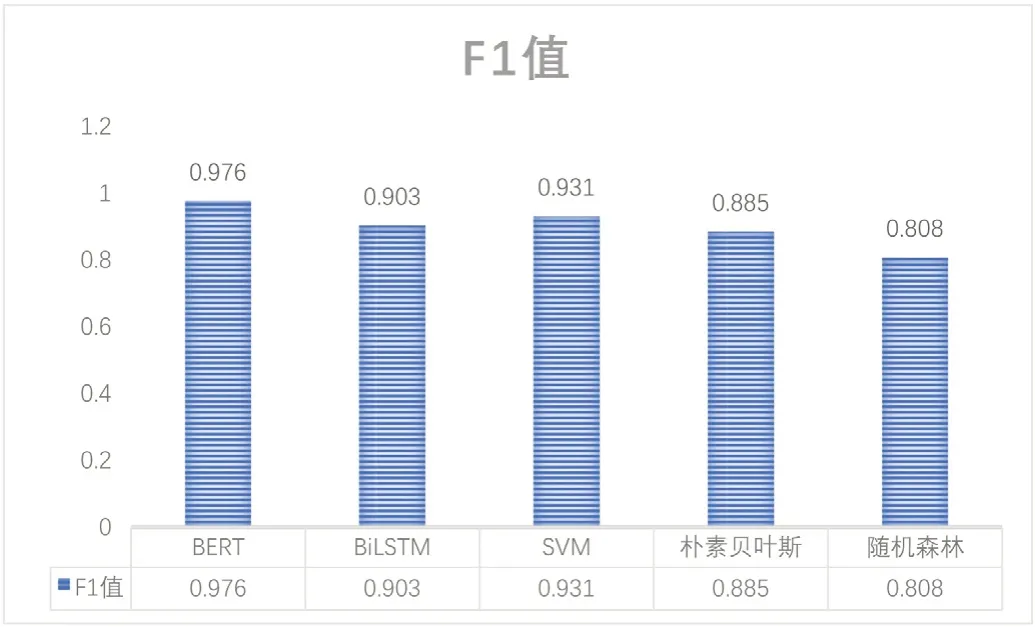
图2:各模型评价指标对比图
其中BERT模型的F1值最高,为0.976,而随机森林的F1值最低,为0.808。BiLSTM、SVM和朴素贝叶斯的F1-score 分别为 0.903、0.931、0.885。
根据模型评价结果证明,对比其他经典的深度学习模型BiLSTM和机器学习模型随机森林,SVM,朴素贝叶斯,
BERT模型的各项评估指标均有所提高,利用 BERT模型对企业的风险进行文本分类和未达标企业的预测,均可获得较为满意的结果。
利用深度学习BERT模型进行企业安全隐患文本分类和不合格企业预测优于其他传统机器学习模型,目前企业安全隐患排查报告文本挖掘的研究较少,一般用传统机器学习方法的研究较多,构建BERT模型能改变以往传统的人工排查企业安全隐患文本的方式,提高排查的效率,比起其他排查方法,各项评价指标都更高,分析结果有利于帮助监管企业安全的管理者做出更加明智的决策,还能排查出不合格的公司,降低企业安全风险,保障企业职工生命健康,营造良好的企业发展环境。
本文介绍了深度学习模型BERT和BiLSTM,机器学习模型随机森林、SVM和朴素贝叶斯相关理论知识,运用编程软件python使用企业安全隐患文本数据集进行训练和测试,得到了BERT模型,BiLSTM模型,随机森林模型,SVM模型,朴素贝叶斯模型对同一企业安全隐患数据集得出的准确率,精准率,召回率和F1值。对实验结果进行对比得出了基于BERT的文本分类模型能够有效实现具有安全隐患的不合格企业的预测,准确率,F1得分等各项指标都在97%以上,因此得出BERT模型进行企业安全隐患文本分类和不合格企业预测的准确性和先进性。为相关监管企业安全的部门做好企业安全监督,安全生产决策的制定提供了辅助决策支持。
猜你喜欢 编码向量预测 选修2—2期中考试预测卷(B卷)中学生数理化·高二版(2022年4期)2022-05-09选修2—2期中考试预测卷(A卷)中学生数理化·高二版(2022年4期)2022-05-09向量的分解新高考·高一数学(2022年3期)2022-04-28住院病案首页ICD编码质量在DRG付费中的应用中国典型病例大全(2022年7期)2022-04-22高效视频编码帧内快速深度决策算法计算机应用(2016年10期)2017-05-12向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23《福彩3D中奖公式》:提前一月预测号码的惊人技巧!金点子生意(2014年4期)2014-04-10不断修缮 建立完善的企业编码管理体系中国计算机报(2009年27期)2009-04-27预测高考中学生英语高效课堂探究(2008年9期)2008-11-17