周 宁,张嵩霖,张 晨
(兰州交通大学电子与信息工程学院 兰州 730070)
全局寻优问题在工程[1-2]、金融[3]、自然科学等领域中广泛存在,求解全局寻优问题有很强的理论与现实意义。现阶段对全局寻优问题求解的重要途径是使用群体智能算法,该算法是受自然界生物的行为模式启发后设计的一类算法,旨在以更快的速度与更高的精度求解复杂的全局寻优问题。近几十年来,群体智能算法发展迅速,如蚁群算法[4-6]、粒子群优化算法[7]、蝙蝠算法[8]、灰狼算法[9]、鲸鱼算法[10]、麻雀搜索算法(sparrow search algorithm,SSA)[11]等。其中,麻雀搜索算法有收敛速度快、收敛精度高、鲁棒性强等优点[12],但同其他群体智能算法一样,它在迭代后期依然有种群多样性减少,容易陷入局部最优的问题。在提高优化算法全局寻优能力方面,文献[13]将遗传算法进行优化,通过在每一代中引入一个较低维度的活动子空间,使算法以较低的成本保证种群的多样性,提高算法的全局寻优能力。文献[14]将牛顿方法与非单调线搜索方法进行结合,当牛顿方法寻优结果不再下降时,使用非单调线搜索帮助寻优,提高算法的全局寻优能力。文献[15]在遗传算法的框架下提出了新的算法,利用历史信息帮助算法自适应地选择局部搜索与全局搜索,提出了新的“诱导”算子,提高了算法的种群多样性,帮助算法收敛至全局最优。
对于麻雀搜索算法的改进是近期群体智能算法研究的热点之一。为了解决麻雀搜索算法中存在的问题,文献[16]引入混沌理论,丰富了种群的多样性,对迭代结果进行混沌扰动,增加算法跳出局部最优的能力;
文献[17]结合鸟群算法,对麻雀搜索算法的位置更新公式进行改进,提高了算法的稳定性;
文献[18]使用混沌理论对麻雀搜索算法进行初始化过程的优化,并且使用危险转移策略与动态演化策略提高了算法的全局寻优能力。
Hammersley[19]序列是一种低差异序列,常被用于图像渲染等领域。在群体智能算法中,Hammersley序列可以应用于种群初始化,提高初始种群的多样性,提升算法的全局搜索能力,相较于随机数生成器与混沌序列有更好的效果,且均匀分布的初始种群可以使粗糙数据推理的论域更加完整。文献[20]介绍了一种名为粗糙数据推理的方法,该方法在数据间建立一种不明确、非确定、似存在的推理关系,与经典逻辑推理不同,粗糙数据推理的对象为数据,保证了该理论可以运用于算法优化中。文献[21]将聚类的思想与进化算法相结合,并通过实验证明了对算法种群进行合理划分,能有效提高算法的寻优能力。
为了提高麻雀搜索的全局搜索能力,加快算法的收敛速度,增加种群的多样性,本文提出一种融合粗糙数据推理的多策略改进麻雀搜索算法(sparrow search algorithm, RSSA)。首 先 基 于Hammersley 点集完成种群初始化,为粗糙数据推理提供完整的论域;
其次使用粗糙数据推理,结合种群的经验建立数据间的推理关系,提高算法的收敛速度,并且增强算法跳出局部最优的能力;
最后对搜索中超界的个体进行优化,保证种群多样性。
麻雀搜索算法主要是受自然界中麻雀觅食与反捕食行为的启发而提出,设计规则为:适应度前20%的个体为发现者,在安全值大于预警值时它们可以进行大范围的搜索,否则将飞往适应度高的安全区域;
除去发现者以外的个体被称为加入者,加入者中适应度靠前的个体将与发现者争夺适应度高的位置,靠后的个体因为竞争激烈,将飞往其他地方进行搜索;
同时种群中有15%的个体会触发预警机制,迅速向适应度较好的区域移动,或者随机移动以靠近其他个体。
麻雀种群及个体表示为:


文献[19]指出,在对寻优问题进行求解时,若解空间的分布未知,则个体的初始值应该在个体空间中尽量均匀地分布,这样可保证种群的多样性,而对于粗糙数据推理,分布均匀的数据集能保证论域的完整,增强粗糙数据推理的完备性。
种群初始化的常用手段有易于实现的随机数生成器和具有随机性、遍历性和规律性等特点的Tent混沌序列[17]。但在大规模寻优问题中,随机数生成器的效果很差,Tent 序列在小周期点及不稳周期点有相邻点相关太强和容易迭代到不动点等缺陷。
低差异序列又称为拟蒙特卡罗序列,是一种确定性的初始化方法,低差异意味着高均匀度,而高均匀度的种群能提高群体智能算法的探索能力,且帮助算法收敛到一个更好的解。常见的低差异序列有Faure、Halton 和Hammersley 等,Hammersley点集在高维度,分布更均匀,更适合在算法优化中使用。Hammersley 二维序列的分布如图1 所示,图中的点分布非常均匀。
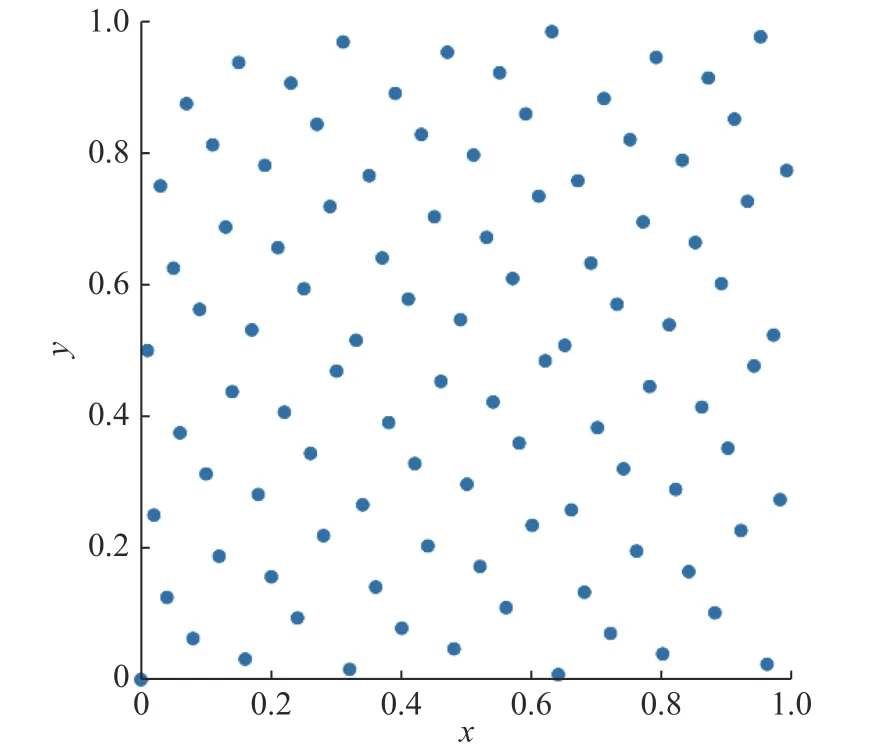
图1 Hammersley 序列的二维分布图
Hammersley 序列初始化种群的方法如下:设个体取值范围为 [xmin,xmax]。由Hammersley 序列产生的第i个准随机数为Ri∈[0,1],则初始种群中个体xi可表示为:
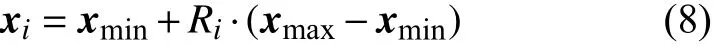
3.1 粗糙集理论
粗糙集思想来源于近似理论,依托于等价关系与近似空间建立,粗糙数据推理则以粗糙集为基础。粗糙集的一些概念和定义如下。
定义 1 设R是数据集U上的等价关系,令U/R={[x]R|x∈U}, 即U/R是U中数据x确 定的R等价类的集合,称U/R为U相对于R的 划分,其中 [x]R为x确 定的R等价类。
结论1 设U是任意一数据集,则U上等价关系的个数与U上划分的个数相同。即U上等价关系R对 应 划 分U/R, 反 之U的 划 分S={S1,S2,···,Sr}对 应等价关系R, 且U/R={S1,S2,···,Sr}。
定义1 与结论1 表明U上的等价关系R和U的划分U/R之间一一对应,而建立划分与等价关系的“桥梁”便是等价类,划分的依据是等价类。
解释粗糙推理需要引入上近似的概念,首先定义近似空间。设U是数据集,R是U上的等价关系,把U和R构 成的结构记为M=(U,R),称为近似空间,其中U称为论域[22],由于近似空间中R的存在可知,对于论域U根据等价关系进行多少种划分,就可得到多少个近似空间。
上下近似的定义建立在近似空间上,设M=(U,R)为 近似空间,则U的任意子集X的上近似与下近似定义如下:
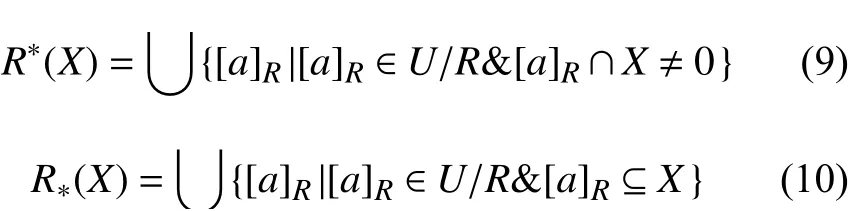
在近似空间M=(U,R)中 ,U/R是U相对于R的划分,上近似和下近似都是通过这个划分进行定义。其中子集X的上近似是所有和X的交集不是空集划分的并,子集X的下近似是等于所有包含在X中的划分的并。
下近似从X内部逼近X,上近似是从X外部逼近,如果X视为精确信息,则上近似包含更多信息。当上下近似空间不相等时称X为粗糙集。
3.2 粗糙推理空间
粗糙推理空间是对近似空间M=(U,R)的扩展。定义粗糙推理空间时,设U是数据集,称为论域,其元素称为数据;
令K={R1,R2,···,Rn},n⩾1,其中R1,R2,···,Rn是U上n个 不同的等价关系;
给定U上的二元关系S⊆U×U, 称S为推理关系。将U、K和S构成的结构记作W=(U,K,S),称为粗糙推理空间。引入粗糙推理空间是为了完善粗糙数据推理,使运作于该空间上的粗糙数据推理理论更加具体、清晰。粗糙推理空间中的S是确定的推理关系,麻雀搜索算法中加入者向最优位置个体靠近的操作便是加入者与最优位置个体间建立了确定的推理关系。
3.3 粗糙数据推理
数据是对象的符号表示,可以是一个数值、一个物体、或者算法的个体信息。如果把推理建立在算法优化中,由确定的位置更新公式,经过推理与演绎得出其他可行的位置更新策略,可以增加种群移动的选择,帮助算法跳出局部最优解,且增大个体收敛到理论最优位置的可能。
实际生活当中存在不明确或潜存于数据之间的粗糙数据联系,挖掘数据潜在联系,给定一些联系规则,使得这些粗糙数据联系有依据地表示,且通过一定的规则程序化粗糙数据联系,即粗糙数据推理[22]。定义粗糙数据推理时,设W=(U,K,S)为粗糙推理空间,对于 ∈S以及R∈K,存在以下3 个定义与2 个引理。
定义2设b∈U,如果b∈R∗([a−R]), 则a关于R直接粗糙推出b, 记作a⇒Rb。
其中 [a−R]称为后继集,其定义为:
[a−R]={x|x∈U且存在z∈[a]R,使得
定 义3b1,b2,···,bn∈U,如果a⇒Rb1,b1⇒Rb2,b2⇒Rb3, ···,bn−1⇒Rbn(n⩾0), 则 称a关 于R粗糙推出b, 记作a|=Rb,容易看出a⇒Rb是a|=Rb的特殊形式。
定义4对于R∈K,a关 于R直 接粗糙推出或粗糙推出b的 推理称为W=(U,K,S)中 的关于R的粗糙数据推理,简称为粗糙数据推理。
引理1[22]设W=(U,K,S)为粗糙推理空间,a,b∈U且R∈K,则a⇒Rb当 且仅当[b]R∩[a−R]ϕ当且仅当[a]R∩[a−R]ϕ。
引理2[22]设R是U上的等价关系,如果a,b∈U, 那么a∈[b]R当 且仅当 [a]R=[b]R当且仅当b∈[a]R。
以上3 个定义确定了基于划分的粗糙数据推理,同理可定义出多种划分下的粗糙数据推理,例如a|=R1b与a|=R2b。在考虑多种划分下的数据推理时可引入嵌入算法[22],该算法作用为:假设a|=R1b与a|=R2b都 成立,若存在等价关系R=R1∩R2,嵌入算法可以判断a|=Rb是否成立。
传统麻雀搜索算法收敛速度较快,但从式(6)、式(7)中容易看出,加入者更新公式与预警机制中都有向全体最优靠拢的操作,这些操作导致算法容易陷入局部最优,且在算法迭代后期种群多样性将严重减少。为了改进以上缺点,本文设计了一种融合粗糙数据推理的多策略改进麻雀搜索算法,通过引入不确定、似存在的模糊关系,增大算法的搜索空间,提高算法跳出局部最优的能力。
粗糙数据推理理论基于上近似理论提出,上近似集包含的潜在联系能极大提高算法的搜索空间,进而提高算法跳出局部最优解的能力,在此证明上近似集具有包含潜在联系等模糊信息的能力。
证明1:在粗糙推理空间下,对任意的x∈X,由等价类的性质可知x∈[x]R, 所以 [x]R∩Xϕ。由上近似R∗(X)的 定义可知[x]R⊆R∗(X), 于是x∈R∗(X),因此X⊆R∗(X)。
由证明1 可知,集合的上近似集由外部逼近该集合,包含更多信息,在麻雀搜索算法中,由于发现者、加入者等个体集合的操作中包含大量靠近局部最优的操作,降低了种群多样性,使用基于上近似的粗糙数据推理理论,便可以包含更多模糊信息,扩大搜索空间,是粗糙数据推理理论能帮助算法跳出局部最优解的有力证明。
对于算法与粗糙数据推理理论结合的合理性,做出如下证明,首先证明粗糙数据推理理论能保留算法确定的收敛操作信息。
证明2:在粗糙推理空间下,对于任意由划分确立的等价关系R∈K,以及算法中的个体a,b∈U,由等价类的定义可知,a∈[a]R。若存在明确的收敛信息∈S,由后继集的定义可知b∈[a−R]。又因为[a−R]⊆R∗([a−R])( 证明1),所以b∈R∗([a−R]),因此可得a⇒Rb或a|=Rb(定义2)。
通过证明2 可得到如下结论。
结论2 对于算法个体a,b∈U,若存在确定的收敛信息 ∈S,则对任意基于划分的等价关系R∈K,有a⇒Rb或a|=Rb。
该结论阐明了粗糙数据推理能保证算法确定的收敛信息不丢失,是粗糙数据推理理论可与算法相结合的先决条件。
其次证明粗糙数据推理理论能引入模糊信息,扩大算法的搜索空间。
证明3:在粗糙推理空间下,对于任意由划分确立的等价关系R∈K,以及算法中的个体a,b,u,v∈U,若存在确定的 ∈S,则a⇒Rb(证明2),故[b]R∩[a−R]ϕ( 引理1)。当u∈[b]R时 ,由于[u]R∈[b]R( 引理2),所以 [u]R∩[a−R]ϕ, 可得a⇒Ru(引理1)。同样,当v∈[a]R时易知v⇒Rb。
通过证明3 可得到如下结论。
结论3 设W=(U,K,S)为粗糙推理空间,如果R∈K且a,b,u,v∈U,则有:
1)若a⇒Rb, 则当u∈[b]R时 ,有a⇒Ru;
2)若a⇒Rb, 则当v∈[a]R时,有v⇒Rb。
该结论表明,粗糙数据推理挖掘出了模糊信息,通过已有确定的收敛信息,合理的将具有粗糙联系的u,v引入,扩大了算法的搜索空间,帮助算法跳出局部最优解,是粗糙数据推理理论与算法结合可行的有力证明。
证明2 与证明3 证明了粗糙数据推理理论能与麻雀搜索算法有机结合,且能完成引入该理论的预期目标,同时也一定程度上解决了群体智能算法在优化时,改进方案多从实验与经验出发,可解释性差的问题。
定义1 与结论1 阐述了等价关系与划分的对应关系,所以粗糙数据推理基于等价关系建立也可称为依据划分建立。
根据麻雀搜索算法原理做以下划分:1)依照适应度划分,其对应等价关系关系记为R1;
2)依照高纬欧氏距离划分,其对应关系记为R2。高纬欧氏距离公式为:

在麻雀搜索算法运行过程中,假设发生了加入者xi向 最优个体 xp靠拢的操作,即认为出现了确定推理
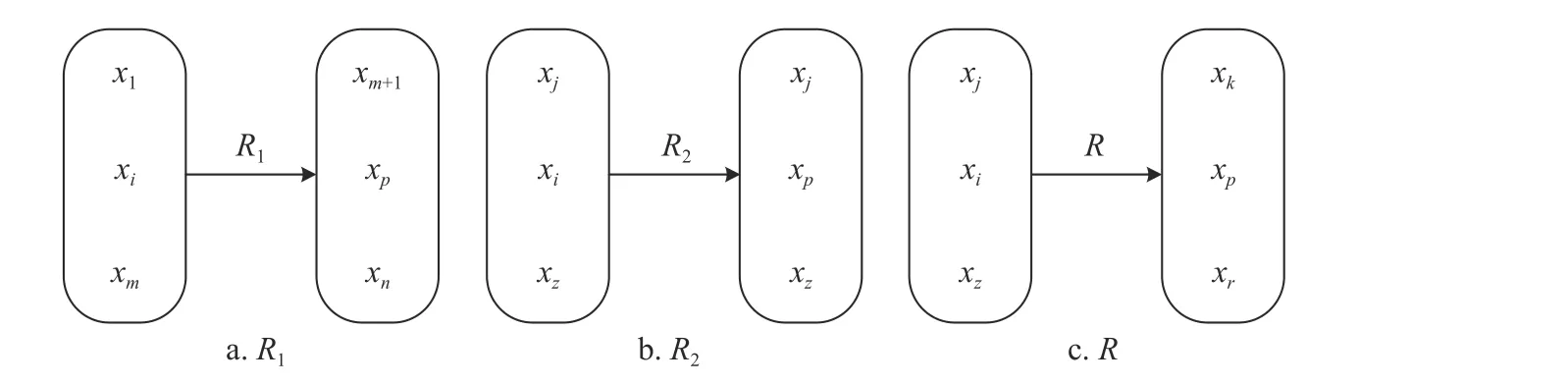
图2 R1、R2 和R 的粗糙推理关系
接下来建立另一种推理关系,它由以下函数推出:
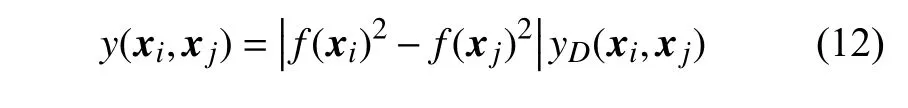
式中,f(xi)2−f(xj)2表 示xi、xj个体适应度的平方差yD(xi,xj)为xi、xj两点间的欧式距离。该函数考虑到个体间的适应度与欧氏距离,使用式(12)对xi与 xp分别求出占总体数量10%的互不相同的个体,依据个体将论域划分,假设该划分对应的等价关系为R, 且已知R=R1∩R2,同样可得图2c 所示的推理关系,由嵌入算法可得该推理关系成立,从而可融合粗糙数据推理理论对麻雀搜索算法进行如下改进:在
1) 当xi向 xp靠 拢时,在 xp的R2等价类中随机选择一个个体xj靠拢。
2) 当xi向 xp靠 拢时,同时在 xp的R1等价类中随机选择一个个体xm+1靠拢,依据适应度贪心选择xi的靠拢对象。
3) 当xi向 xp靠 拢时,同时在 xp的R等价类中随机选择一个个体xk靠 拢,依据适应度贪心选择xi的靠拢对象。
3 种策略的推理关系如图3 所示。
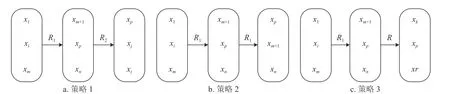
图3 3 种策略的推理关系
RSSA 的算法流程图如图4。
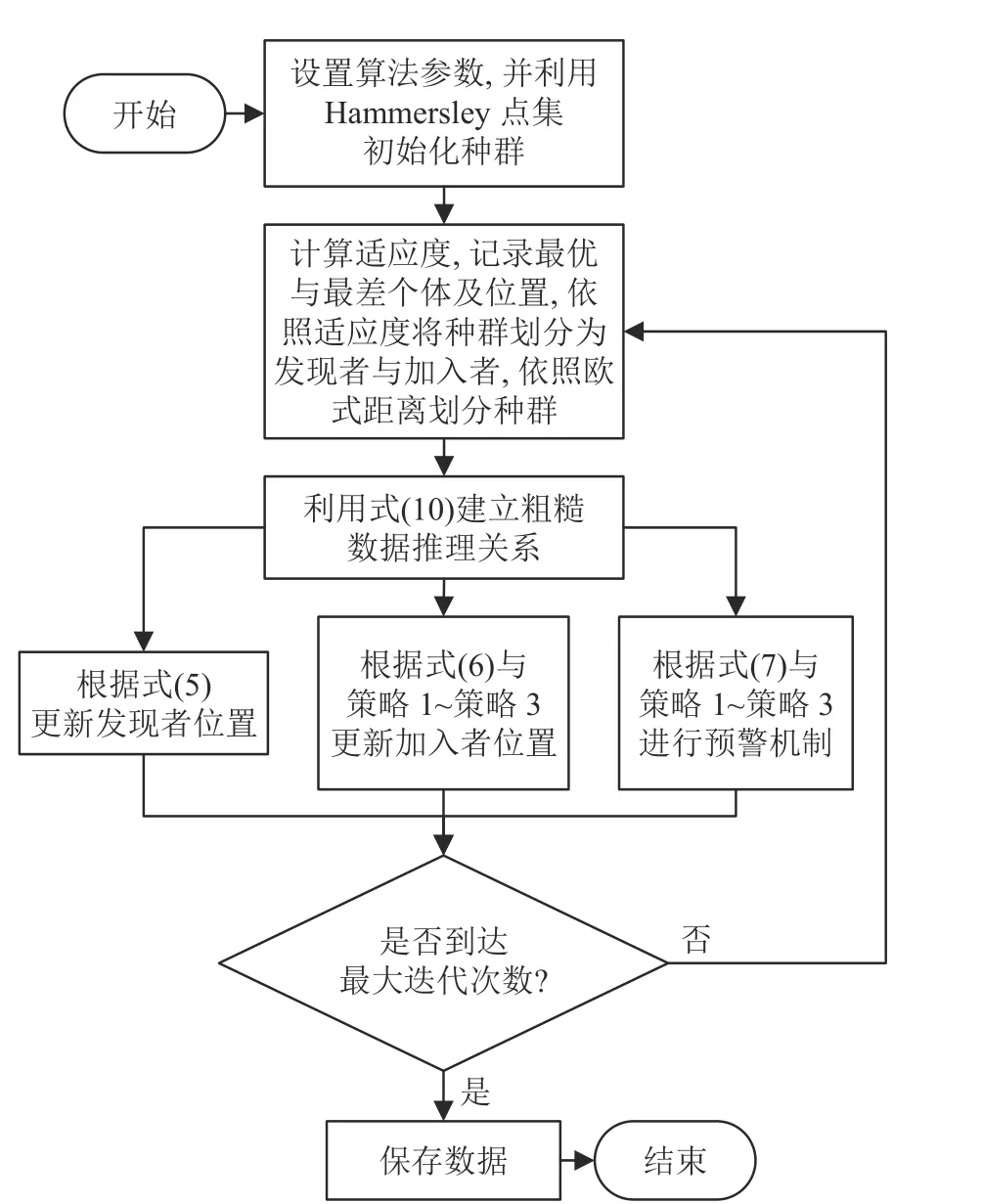
图4 RSSA 算法流程图
5.1 策略执行概率分析
采用正交实验分析3 种策略执行概率对RSSA寻优能力的影响,测试函数如表1 所示。依据当前迭代次数与最大迭代次数的比值将算法划分为前、中、后期,对应关系为前期[0, 0.15]、中期(0.15,0.8]、后期(0.8, 1]。算法的种群个数为100,迭代次数为500,独立运行10 次,求出收敛至最优值时迭代次数的平均值,若未收敛至最优则最小迭代次数取500。表2 为函数F1 的正交实验统计结果。
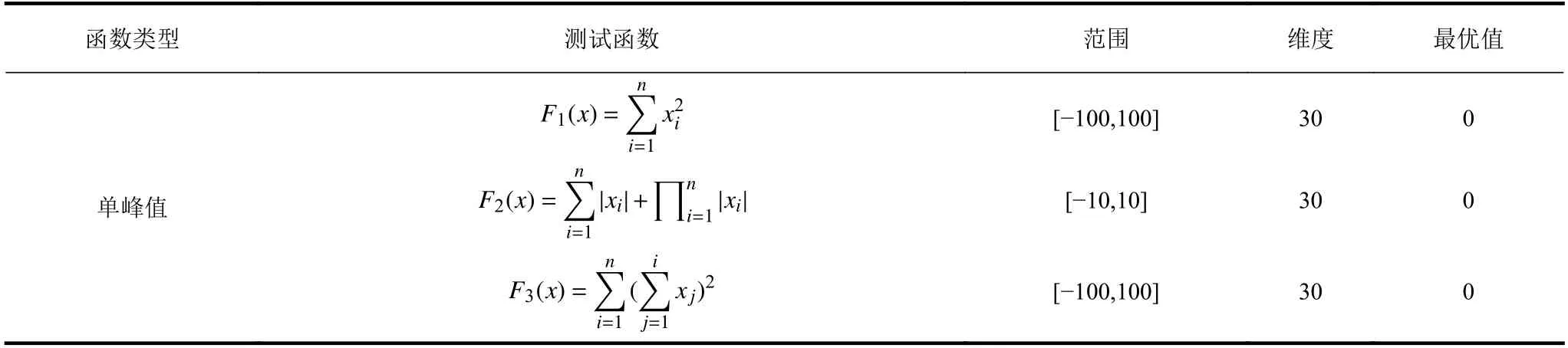
表1 待测试函数
由表2 可知,组合1 的最优迭代次数平均值最小,所以函数F1 采用组合1 的执行概率,对其他函数采用同样的组合进行正交实验,得到最佳的执行概率组合结果,如表3 所示。
由表3 可知,函数对执行概率有敏感度,但结合表2 与表3 可以看出组合1 对比其他组合有一定的优势,对于最优解未知函数而言,从算法普遍适用性的角度出发可以先采用组合1 的执行概率,为了追求收敛速度与精度,则应对不同函数采用不同的策略执行概率组合。
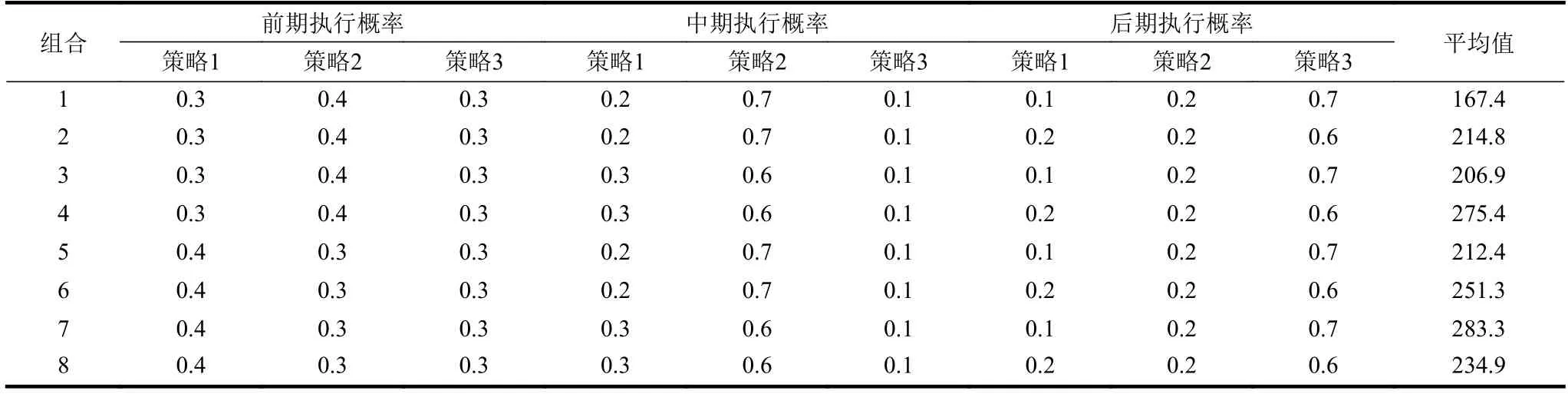
表2 F1 正交实验结果
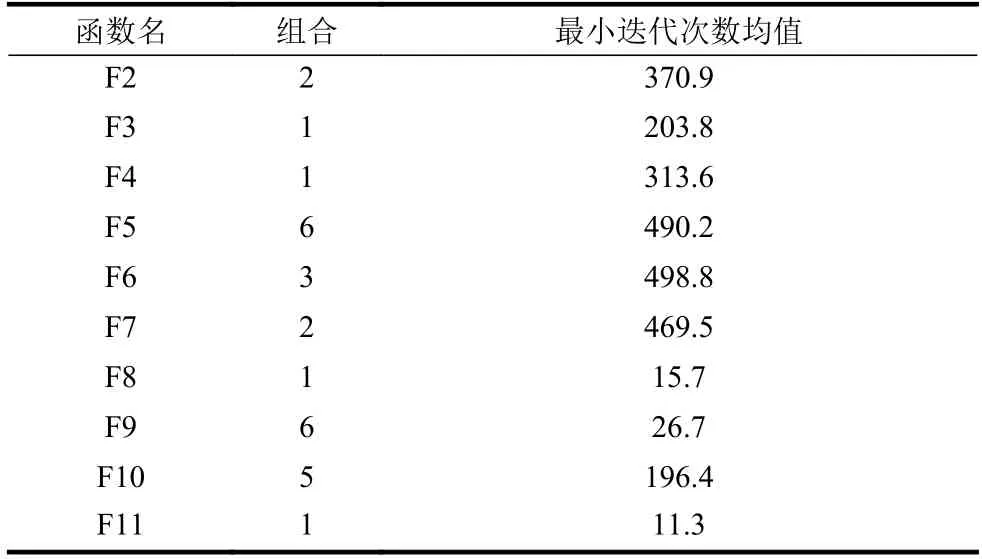
表3 剩余函数正交实验结果

续表
5.2 策略合理性分析
策略1 使用依托高维欧氏距离的划分,增大了算法的搜索范围,使算法具有了跳出局部最优的能力;
策略2 使用依托适应度的划分,提高了算法的收敛速度;
策略3 使用式(12)推导出的划分,从高维欧氏距离与适应度两个方面同时逼近最优值,提高算法的收敛精度。为了证明以上推论,使用SSA 与RSSA 进行多次对比实验,选择对算法收敛能力与跳出局部最优能力要求较高的函数,如表1中的F6、F9 和F10,绘制其中一次实验的收敛曲线如图5 所示。对比实验的种群个数为50,迭代次数为100。
从图5a、图5b 的左小框部分可以看出,在算法运行的初期由于策略1 的影响,算法的收敛速度与SSA 相比并不快,且有一定波动,说明算法牺牲了收敛速度扩大了搜索范围增大;
从图5c 的左长方形框部分可以看出,在算法运行的中期由于主要执行策略2,算法的收敛速度大幅度提升;
从图5a、图5c 的中间小框部分可以看出,由于3 种策略的共同影响,算法具有了跳出局部最优的能力,且在跳出局部最优后能够继续向最优解收敛,或收敛至最优解;
从图5a 的右小框部分可以看出,在算法运行的后期策略1 与策略3 的共同影响下,算法的收敛速度放缓,但是精度提高,收敛曲线表明算法在迭代中后期已经陷入局部最优,但由于策略1 的影响,算法最终跳出局部最优并开始向全局最优收敛。对比实验证明粗糙数据推理理论的引入达到了预期的效果。

图5 收敛曲线对比
5.3 时间复杂度分析
时间复杂度是评价算法执行效率的重要指标。假设求解问题规模是D维,麻雀种群规模为正整数N,求解目标函数所需的时间为f(D)。文献[23]指出传统麻雀搜索算法的时间复杂度为:

麻雀搜索算法位置更新公式的时间复杂度为:

在RSSA 中,产生一个D维Hammersley 序列的时间复杂度为T=O(D),但基于Hammersley 序列的初始化方法是一种确定性的初始化方法,在确定算法个体数N后仅需执行一次,便可作为本地信息直接调取。假设调取本地Hammersley 序列所需执行时间为t1,按式(8)生成单个个体所需时间为t2,则RSSA 的初始化种群时间复杂度为:
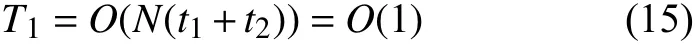
策略1 需要依据高维欧氏距离进行划分,假设计算一次D维欧式距离耗时为t3D,共需计算N−1次,总耗时(N−1)t3D;
且需要随机选择一个个体向其靠拢,随机选择个体耗时t4,靠拢操作与具体的位置更新公式耗时相同,复杂度为O(D),所以策略1 的时间复杂度为:
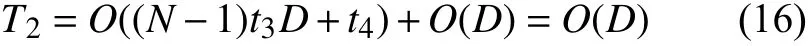
策略2 需要依据适应度进行划分,计算一次D维函数耗时为f(D),共需计算N−1 次,总耗时(N−1)f(D);
同样需要随机选择一个个体执行靠拢操作,随机选择个体耗时t5,靠拢操作复杂度为O(D),且需要进行贪心选择,即计算两次D维函数,并进行对比,该操作耗时2f(D)+t6。所以策略2 的时间复杂度为:
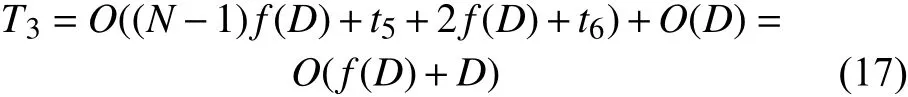
在计算策略3 前,依照式(12)计算,需要求解两次D维函数,耗时为2f(D),且计算一次D维欧氏距离,耗时为t7D,式(12)的时间复杂度为:
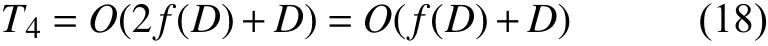
策略3 在划分后,还需要随机选择个体进行靠拢操作与贪心选择,所以策略3 的时间复杂度为:

故最大迭代次数为itermax时,RSSA 的时间复杂度为:

综上可知,RSSA 与SSA 时间复杂度相同,即基于低差异序列的初始化与粗糙数据推理理论的引入并不会提高算法的时间复杂度。
6.1 实验环境与基准函数
利用3 种不同类型共计11 个测试函数进行对比仿真实验,来验证RSSA 对于麻雀搜索算法改进的科学性以及相较于灰狼优化(grey wolf optimization, GWO)算法、鹈鹕优化算法(Pelican optimization algorithm, POA)[24]、被囊群算法(tunicate swarm algorithm, TSA)[25]、麻雀搜索算法(sparrow search algorithm, SSA)等智能算法的优越性。各测试函数如表1 所示,6 个可变维度的单峰函数F1~F6,4 个可变维度的多峰函数F7~F10,1 个固定维多峰函数F11。为了保证实验的公平性,所有算法的种群个数均为100,迭代次数为500,实验在同一环境下独立运行50 次。将各个算法最优值的平均值与标准差作为评价指标,如表4 所示。

表4 实验结果对比表
6.2 实验结果及分析
通过表4 可以得出,在F1~F6 的高维单峰值函数测试中,RSSA 均优于其他算法多个数量级,除F2 与F5 外,RSSA 算法平均最优值都能收敛到理论最优解0;
标准差是反映数据离散程度的数值,从标准差上可以看出收敛到0 的情况非常稳定,即每次实验都可以得到理论最优解。在F7~F10的高维多峰值函数测试中RSSA 也强于其他算法,跳出局部最优解的能力有所提升,在大多数情况下收敛到最优解0;
对于最优解不在0 处的高维多峰值函数F7,RSSA 算法也最接近最优解−12 569.487,标准差也属于可接受的范围,相较于其他群体智能算法收敛精度更高也更稳定。
为了证明同时引入低差异序列与粗糙数据推理的必要性,选取对算法收敛速度与跳出局部最优能力要求较高的多峰值函数F7~F10,分别对SSA、引入低差异序列的SSA、引入粗糙数据推理的SSA 和RSSA 进行对比实验。实验的种群个数与迭代次数分别为100 和500,独立运行30 次记录找到的最优解结果如表5 所示。

表5 多峰值函数不同策略对比表
通过表5 可得,对于简单的多峰值函数F8,4 种算法都能收敛到最优解,说明每种改进单独存在都是可行的,而对于复杂的多峰值函数,在单独引入低差异序列或粗糙数据推理后,算法的性能都有所提高,但是依然无法收敛到全局最优,在同时引入低差异序列与粗糙数据推理后,RSSA 全局寻优能力增强,求解出了理论最优值。这说明同时引入低差异序列与粗糙数据推理是必要的,进一步证明了粗糙数据推理的引入并非简单地增加策略和迭代中的种群多样性,而是利用适应度、高纬欧氏距离与式(12)中内涵的3 种等价关系进行策略的推理,通过表2、表3 执行概率控制。在算法执行过程中,将推理出的3 种策略有机的结合,自适应地选择,最终保证算法能够兼顾收敛速度与搜索范围,增大收敛到全局最优的可能。
综上所述,在融合粗糙数据推理以及使用低差异序列进行初始化后,算法具备了跳出局部最优的能力,全局搜索能力也有提升。
为比较5 种算法的收敛性能,本文对5 种算法进行仿真对比,结果如图6 所示。
收敛曲线图反映了算法每次迭代所获得的最优解,当收敛曲线在某次迭代中消失时即代表已经收敛为0。观察图6 可得出结论:RSSA 算法的收敛速度与精度都高于其他算法,能够随迭代次数的增加不断地寻优,多数情况下都可以收敛到理论最优值,全局寻优能力有所提高,相较于其他算法有优势。
为了提高基本麻雀搜索算法解决高维多峰值问题的能力及群体智能算法改进策略的可解释性,本文将粗糙数据推理与麻雀搜索算法合理融合,提出了一种融合粗糙数据推理的多策略改进麻雀搜索算法(RSSA),并使用3 种类型共计11 个测试函数对RSSA 进行性能测试,与灰狼算法(GWO)、鹈鹕优化算法(POA)、被囊群算法(TSA)等群体智能算法以及传统麻雀搜搜算法(SSA)算法进行对比,得出以下结论:
1) RSSA 的优化效果明显,算法性能提升较大,且可有效地跳出局部最优解。2) 11 个基准函数的对比实验结果与收敛曲线表明:RSSA 算法在收敛速度、收敛精度与跳出局部最优的能力上优于其他算法。后续将把RSSA 算法应用在求解具体的工程问题中。
猜你喜欢 搜索算法复杂度适应度 改进的自适应复制、交叉和突变遗传算法计算机仿真(2022年8期)2022-09-28一种基于分层前探回溯搜索算法的合环回路拓扑分析方法现代电力(2022年2期)2022-05-23一类长度为2p2 的二元序列的2-Adic 复杂度研究*密码学报(2021年4期)2021-09-14改进的非结构化对等网络动态搜索算法军民两用技术与产品(2021年2期)2021-04-13改进的和声搜索算法求解凸二次规划及线性规划烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19毫米波MIMO系统中一种低复杂度的混合波束成形算法成都信息工程大学学报(2021年6期)2021-02-12Kerr-AdS黑洞的复杂度华东师范大学学报(自然科学版)(2020年1期)2020-03-16非线性电动力学黑洞的复杂度华东师范大学学报(自然科学版)(2019年2期)2019-06-11基于莱维飞行的乌鸦搜索算法智能计算机与应用(2018年3期)2018-09-05启发式搜索算法进行乐曲编辑的基本原理分析当代旅游(2016年10期)2017-04-17